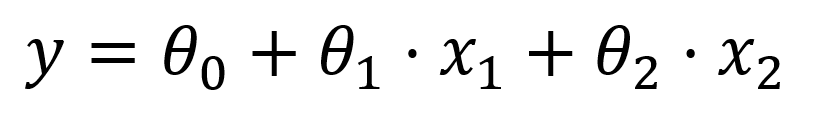Θα δούμε πώς μπορούμε να πάρουμε έναν πίνακα με πωλήσεις μεταχειρισμένων αυτοκινήτων και να προβλέψουμε σε τι τιμή θα μπορεί να πουληθεί ένα αυτοκίνητο με βάση κάποια χαρακτηριστικά του. Για παράδειγμα το μοντέλο μας θα μπορεί να παίρνει σαν είσοδο το μοντέλο του αυτοκινήτου, τα χιλιόμετρα του, τα αλογά του και άλλα χαρακτηριστικά και να μας λέει ποια είναι η αξία του.
Σε αυτό το μάθημα θα πάρουμε έναν πίνακα με τις πωλήσεις, θα δούμε τι μπορούμε να κάνουμε εάν έχει κενές τιμές κάποια στήλη, πώς μπορούμε να φέρουμε τον πίνακα στην μορφή που πρέπει για να μπορέσουμε να χρησιμοποιήσουμε κάποιον αλγόριθμο ώστε να προβλέψουμε την τιμή των αυτοκινήτων.
Το μάθημα είναι γραμμένο στην γλώσσα Pythonκαι οι βιβλιοθήκες που θα δούμε κυρίως είναι η Pandas για να “καθαρίσουμε” τον πίνακα, να αναλύσουμε τα δεδομένα και να φέρουμε τον πίνακα στην μορφή που θέλουμε. Η βιβλιοθήκη Scikit-Learn για το κομμάτι του Machine Learning και τις βιβλιοθήκεςmatplotlib / seabornγια το κομμάτι του visualization.
Σκοπός του Μαθήματος
Σκοπός του μαθήματος είναι να δούμε την διαδικασία από την αρχή μέχρι το τέλος για το πως μπορούμε να χρησιμοποιήσουμε έναν αλγόριθμο για να προβλέψουμε την τιμή των μεταχειρισμένων αυτοκινήτων.
Το μάθημα θα εστιάσει περισσότερο στο κομμάτι του Machine Learning και λιγότερο στην ανάλυση και τον καθαρισμό των δεδομένων. Παρόλο που θα δούμε την διαδικασία από την αρχή έως το τέλος καλο θα ήταν να έχετε μια βασική γνώση της γλώσσας Python και των βιβλιοθηκών pandas και matplotlib.
Τι είναι το Machine Learning
Το Machine Learning είναι ένας κλάδος της τεχνητής νοημοσήνης που εστιάζει στην χρήση δεδομένων και αλγορίθμων με σκοπό να αναλύσει και να ερμηνεύσει τα μοτίβα που υπάρχουν μέσα στα δεδομένα για να μπορέσει να μάθει χωρίς την βοηθειά μας. Ο τρόπος που μαθαίνει εξαρτάται από ποιον αλγόριθμο θα χρησιμοποιήσουμε αλλά σε γενικές γραμμές:
Παίρνει τα δεδομένα και δοκιμάζει μία λύση
Βλέπει πόσο λάθος είναι η δικιά του λυσή σε σχεση με την πραγματικότητα
Και ξαναδοκιμάζει άλλη λύση μέχρι να φτάσει σε μία που να είναι κοντά στην πραγματική.
Πότε χρησιμοποιούμε το Machine Learning
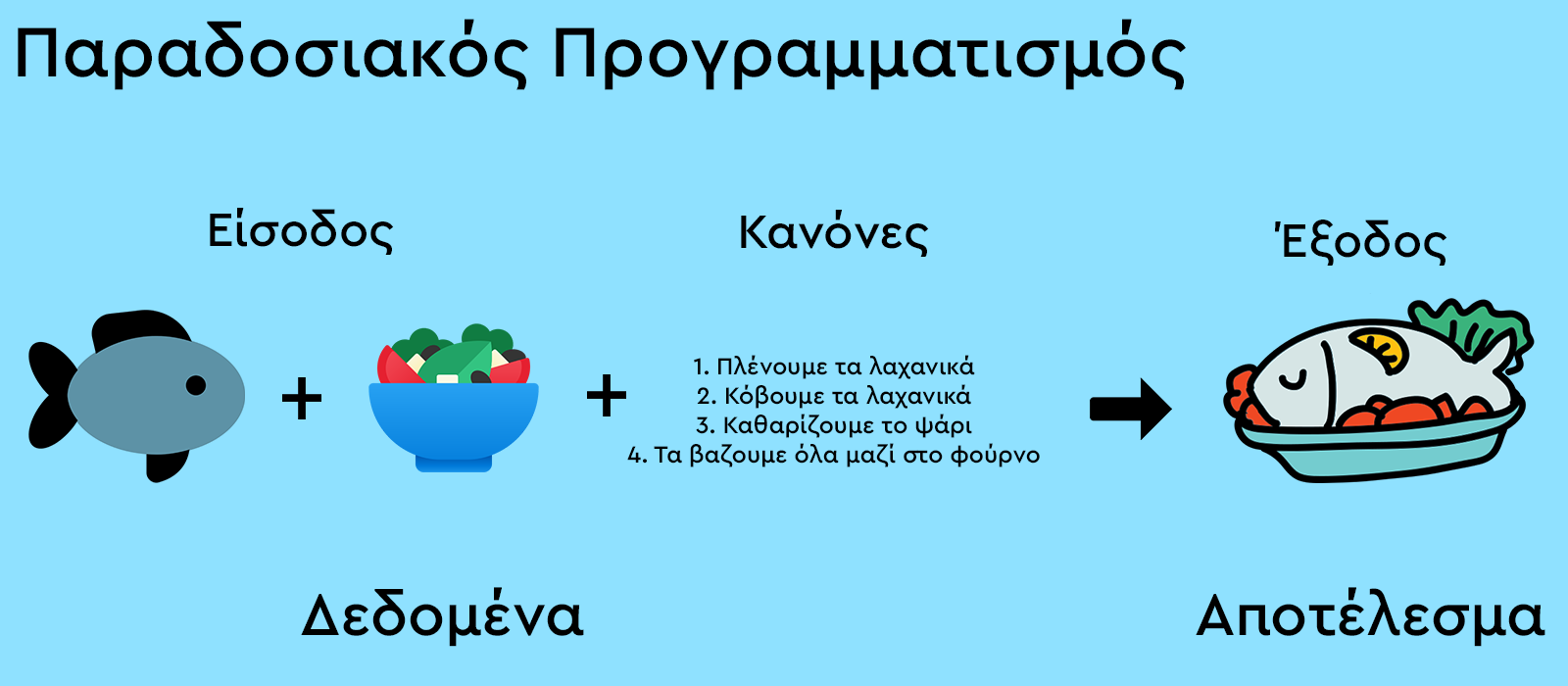
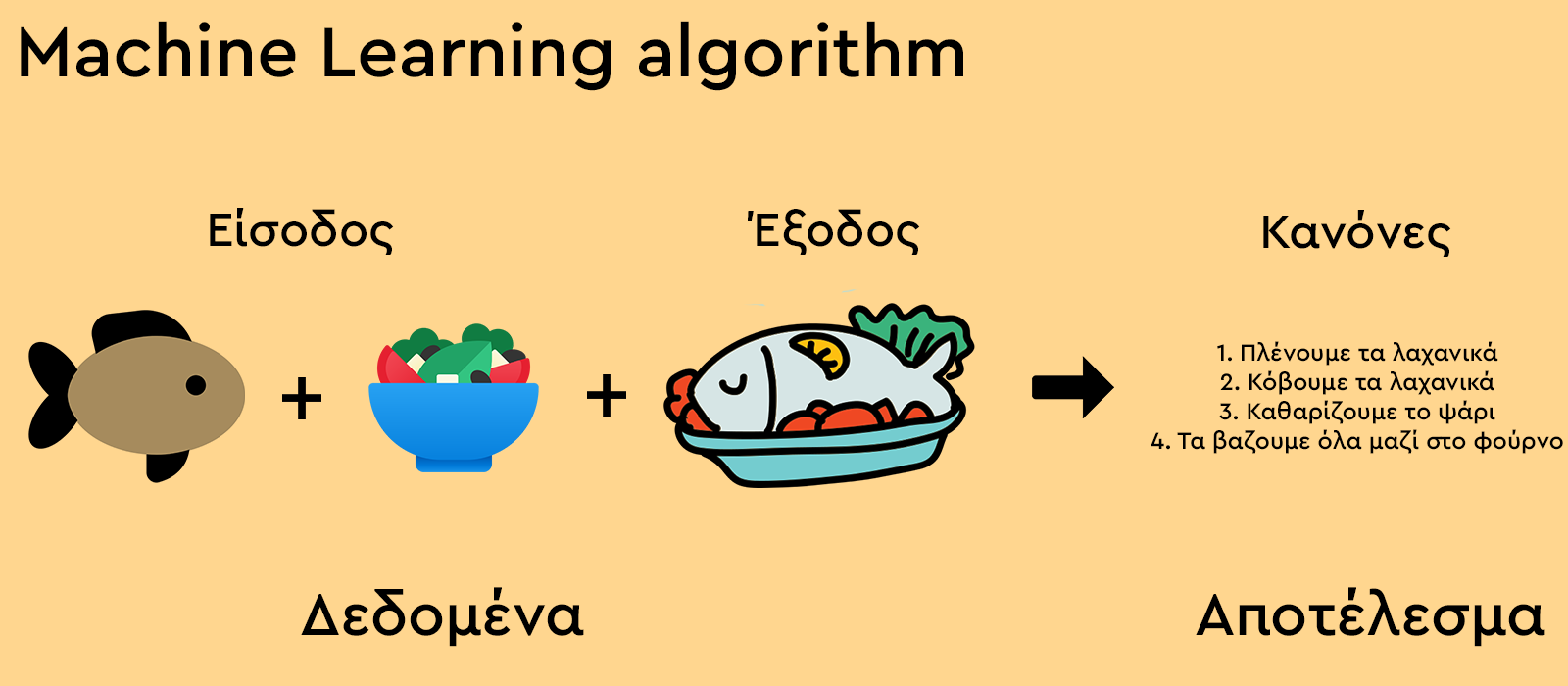
Όταν θέλουμε να φτάσουμε σε ένα αποτέλεσμα χωρίς να έχουμε γνωστές τις παραμέτρους του προβλήματός μας τότε χρησιμοποιήουμε το Machine Learning. Εάν έχουμε γνωστές τις παραμέτρους ή μπορόυμε να τις βρούμε εύκολα μόνοι μας τότε χρησιμοποιούμε τον “παραδοσιακό προγραμματισμό”. Ας δούμε ένα παράδειγμα με τις διαφορές ανάμεσα σε “παραδοσιακό προγραμματισμό” και Machine Learning για να το καταλάβουμε καλύτερα.
Η διαφορά στο συγκεκριμένο παράδειγμα είναι ότι στον παραδοσιακό προγραμματισμό δίνουμε στον υπολογιστή τα υλικά και την συνταγή και ο υπολογιστής μας φτιάχνει το φαγητό. Στην περίπτωση του Machine Learning δίνουμε στον υπολογιστή τα υλικά και το τελικό φαγητό και μας υπολογίζει ποια βήματα πρέπει να ακολουθήσουμε για να φτιάξουμε το έτοιμο φαγητό.
Ας ξεκινήσουμε να τα δούμε και στην πράξη.
Πρόβλεψη τιμής μεταχειρισμένων αυτοκινήτων
Ορισμός προβλήματος:
Θα προσπαθήσουμε να προβλέψουμε την τιμή των μεταχειρισμένων αυτοκινήτων χρησιμοποιόντας δεδομένα από παλιές πωλήσεις αυτοκινήτων.
Για να αξιολογήσουμε το μοντέλο μας θα χρησιμοποιήσουμε το accuracy.
Στήλες / Χαρακτηριστικά:
Name: Η μάρκα και το μοντέλου του αυτοκινήτου
Location: Η πόλη στην οποία πουλήθηκε το αυτοκίνητο
Year: Η χρονιά κατασκευής του αυτοκινήτου
Kilometers_Drive: Τα συνολικά χιλιόμετρα του αυτοκινήτου
Fuel_Type: Ο τύπος καυσίμου του αυτοκινήτου (Βενζίνη, πετρελαίο κλπ)
Transmission: Ο τύπος του κιβοτίου του αυτοκινήτου (Χειροκίνητο, αυτόματο)
Owner_Type: Εάν το αυτοκίνητο είναι πρώτο χέρι, δεύτερο κλπ
Mileage: Κατανάλωση καυσίμου σε km/kg ή σε kmpl
Engine: Τα κυβικά του αυτοκινήτου
Power: Τα άλογα του αυτοκινήτου
Seats: Πόσες θέσεις έχει το αυτοκίνητο
New_price: Πόσο πουλήθηκε το αυτοκίνητο σαν καινούργιο
Price: Πόσο πουλήθηκε το αυτοκίνητο σαν μεταχειρισμένο
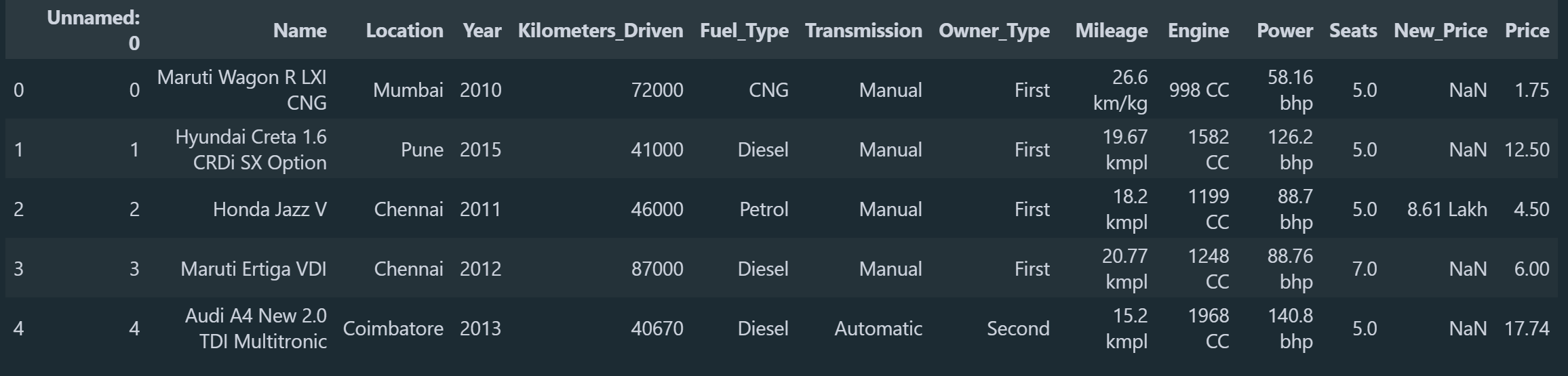
Αφού είδαμε και λίγο τα δεδομένα μας ας ξεκινήσουμε να γράφουμε τον κώδικα. Αρχικά θα εισάγουμε κάποιες βιβλιοθήκες που θα χρησιμοποιήσουμε συχνά και στην συνέχεια θα εισάγουμε το αρχείο με το όνομα train-data.csv και θα δημιουργήσουμε ένα dataframe.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# load data / create dataframe
df = pd.read_csv('data/train-data.csv')
df.head()
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# load data / create dataframe
df = pd.read_csv('data/train-data.csv')
df.head()
Clean Data
Εκτός και αν έχουμε δημιουργήσει μόνοι μας τον πίνακα σχεδόν πάντα θα υπάρχει κάποιο πρόβλημα με τα δεδομένα μας, αυτα μπορεί να είναι κάποια κενά κελιά, κάποιες λάθος τιμές κλπ. Οπότε θα πρέπει πάντα να ελέγχουμε τον πινακά μας για τέτοιες περιπτώσεις και να τις διορθώνουμε. Αρχικά ας διαγράψουμε την στήλη Unnamed: 0 μιας και δεν θα μας χρειαστεί κάπου.
# drop the extra index column
df.drop(columns='Unnamed: 0', inplace=True)
Αυτό που μπορεί να παρατηρήσατε είναι ότι στην στήλη με το όνομα του αυτοκινήτου αναφέρει πολλές λεπτομέρειες για το μοντέλο του αυτοκινήτου. Ας δούμε λίγο πόσα διαφορετικά μοντέλα υπάρχουν σε σχέση με όλα τα δεδομένα.
# check unique values from Name column
df.Name.nunique(), len(df)
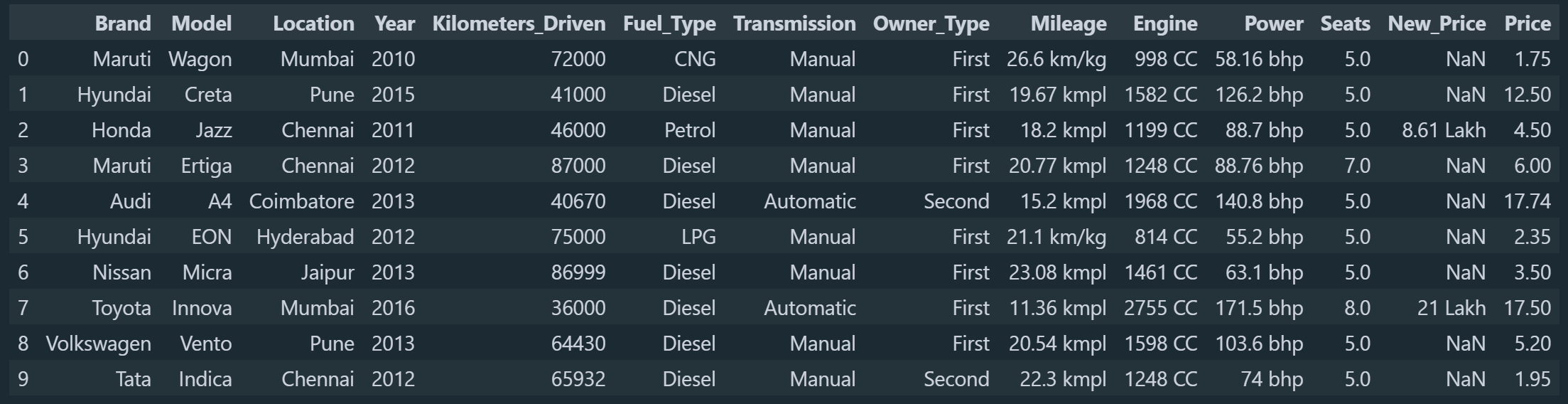
1876 διαφορετικά μοντέλα σε 6019 γραμμές. Οι πολλές διαφορετικές τιμές σε μία στήλη θα μειώσουν την αποτελεσματικότητα του αλγόριθμού μας καθώς θα είναι πολύ δύσκολο να βρεί κάποια μοτίβα για να μάθει. Γι’ αυτό το λόγο θα δημιουργήσουμε δύο στήλες όπου θα κρατήσουμε μόνο την μάρκα και το μοντέλου του αυτοκινήτου αλλά χωρίς τις λεπτομέρειες για την έκδοσή του. Εαν παρατηρήσουμε καλά θα δούμε ότι σε όλες τις γραμμές η πρώτη λέξη είναι η μάρκα και η δεύτερη το μοντέλο οπότε είναι εύκολο να κρατήσουμε αυτες τις δύο. Αρχικά θα επιλέξουμε την στήλη που θέλουμε, θα κάνουμε split τις λέξεις και θα επιλέξουμε την πρώτη και μετά την δεύτερη λέξη αντίστοιχα. Στην Python μετράμε από το 0, γι’ αυτό θα επιλέξουμε τις λέξεις που είναι στην θέση 0 και 1. Στην συνέχεια θα διαγράψουμε την παλιά στήλη.
# keep only the brand and model (in separate columns)
df['Brand'] = df.Name.str.split(' ', expand=True)[[0]]
df['Model'] = df.Name.str.split(' ', expand=True)[[1]]
df.drop(columns='Name', inplace=True)
Στην συνέχεια αν θέλουμε μπορούμε να αλλάξουμε την σειρά των στηλών και να φέρουμε τις δύο νέες στήλες που δημιουργήσαμε στο τέλος του πίνακα στην αρχή.
Ας ξαναδούμε τώρα πόσες μοναδικές τιμές έχουμε στην στήλη Brand και στην στήλη Model.
# look the unique values from brand and model
df.Brand.nunique(), df.Model.nunique()
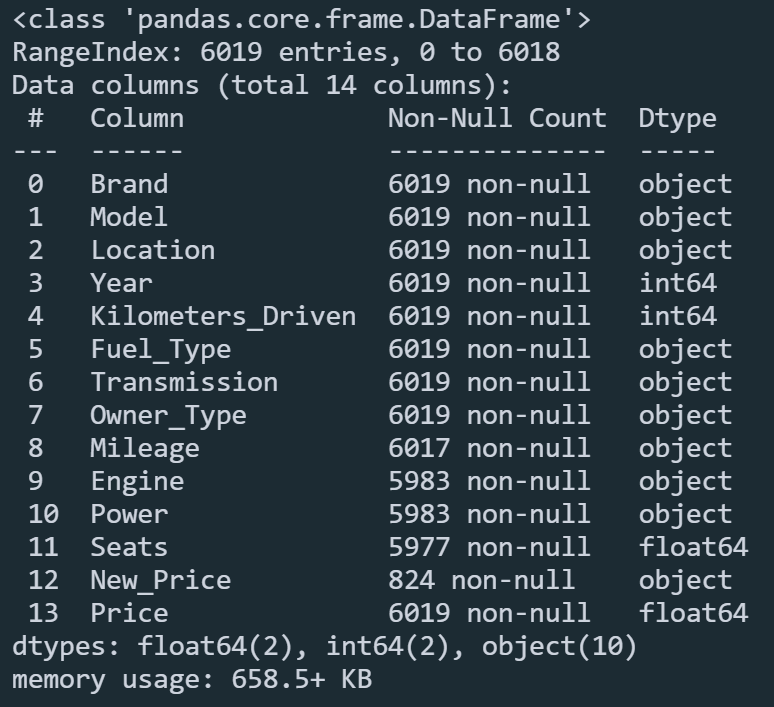
Τώρα βλέπουμε ότι έχουμε 31 και 212 μοναδικές τιμές αντίστοιχα, πολύ καλύτερα από τις 1876 που είχαμε πριν. Στην συνέχεια ας δούμε πόσα κενά κελιά έχουμε σε κάθε στήλη.
df.info()
Ας ξεκινήσουμε με την στήλη Mileage. Θα συμπληρωσουμε τα κενά κελιά με την πιο επαναλαμβανόμενη τιμή.
Στην συνέχεια θέλουμε να αφαιρέσουμε τις λέξεις km/kg και kmpl και να μετατρέψουμε την στήλη από τύπου string σε float. Εφόσον υπάρχουν δύο διαφορετικές μονάδες μετρήσεις θα πρέπει να μετατρέψουμε και την μία στο ίδιο μέγεθος με την άλλη. Εμείς εδώ θα κρατήσουμε τις τιμές με το kmpl, οπότε τις τιμές με το km/kg θα πρέπει να τις μετατρέψουμε σε kmpl.
# remove str from Mileage and convert
mileage_kmpl = []
for row in df.Mileage:
if 'km/kg' in str(row):
mileage_kmpl.append(round(float(row[:-6]) * 1.35, 2))
elif 'kmpl' in str(row):
mileage_kmpl.append(round(float(row[:-5]), 2))
df['Mileage'] = mileage_kmpl
# rename column to Mileage_kmpl
df.rename(columns={'Mileage': 'Mileage_kmpl'}, inplace=True)
Στην συνέχεια θα αφεραίσουμε τα γράμματα CC από την στήλη Engine, θα συμπληρώσουμε τα κενά κελιά με την διάμεση τιμή και θα μετατρέψουμε τον τύπο της στήλης σε ακέραιο.
Επόμενη στήλη είναι η στήλη Power, αυτή η στήλη πέρα από κενά κελιά έχει και κελία με την τιμή “null bhp”. Οπότε αρχικά θα αντικαταστήσουμε αυτά τα κελιά με την πιο διαδεδομένη τιμή της στήλης.
Και στην συνέχεια θα αφαιρέσουμε την λέξη bhp, θα συμπληρώσουμε τα κενά κελιά με την πιο διαδεδομένη τιμή της στήλης και θα μετατρέψουμε την στήλη σε δεκαδικό αριθμό.
Στην στήλη Seats θα συμπληρώσουμε τα κενά κελιά με την διάμεση τιμή και θα διαγράψουμε τις σειρές που έχουν σαν τιμή το 0. Μιας και πρόκειται για λάθος αφού δεν υπάρχει αυτοκίνητο με 0 θέσεις.
Aς διαγράψουμε την στήλη New_Price αφού τα περισσότερα κελιά της είναι άδεια, επίσης από την στήλη Fuel_Type θα διαγράψουμε τα αυτοκίνητα που είναι ηλεκτρικά αφού είναι πολύ λίγα και δεν θα βοηθήσουν το μοντέλο μας να μάθει κάτι χρήσιμο.
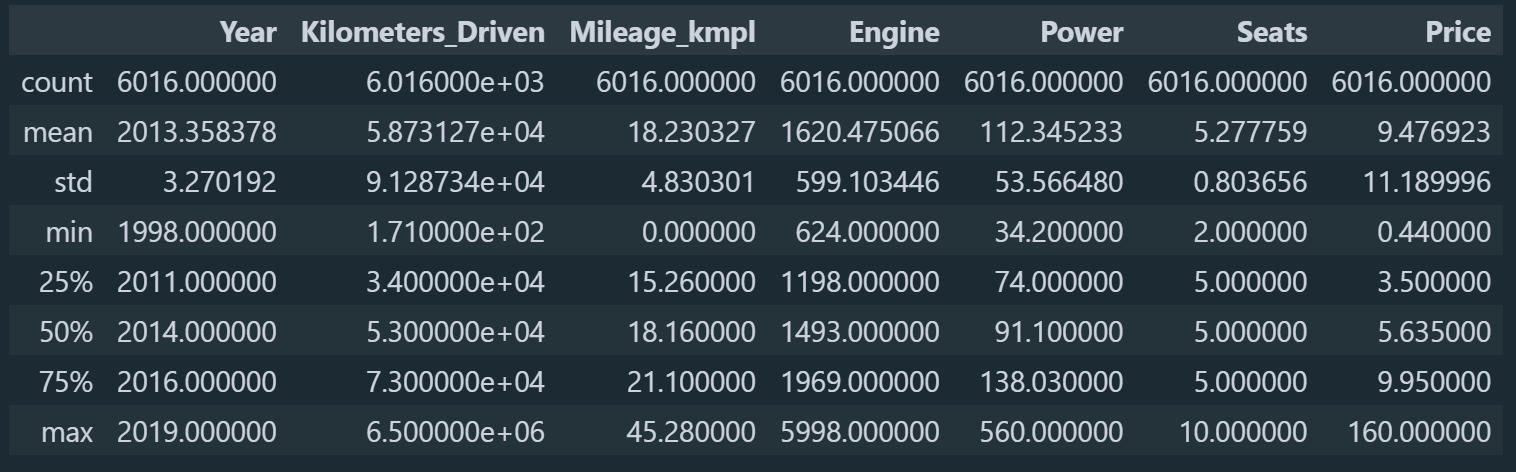
Ας δούμε τώρα κάποια στατιστικά στοιχεία για όλο τον πίνακα.
df.describe()
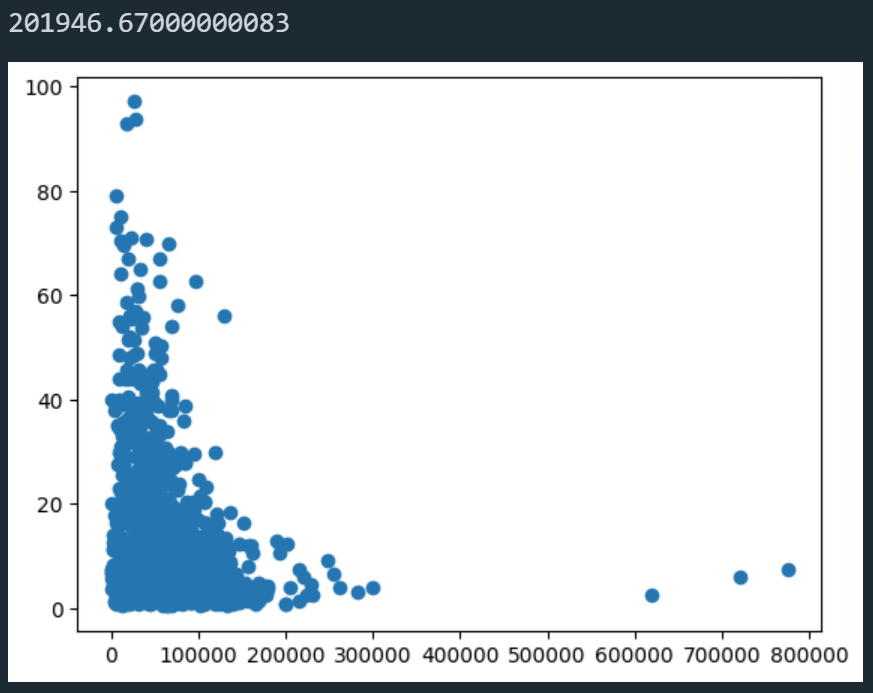
Κάτι που μπορούμε να παρατηρήσουμε είναι ότι η στήλη Kilometers_Driven φαίνεται να έχει κάποιες ακραίες τιμές, ας το δούμε λίγο σε ένα διάγραμμα για να το καταλάβουμε καλύτερα.
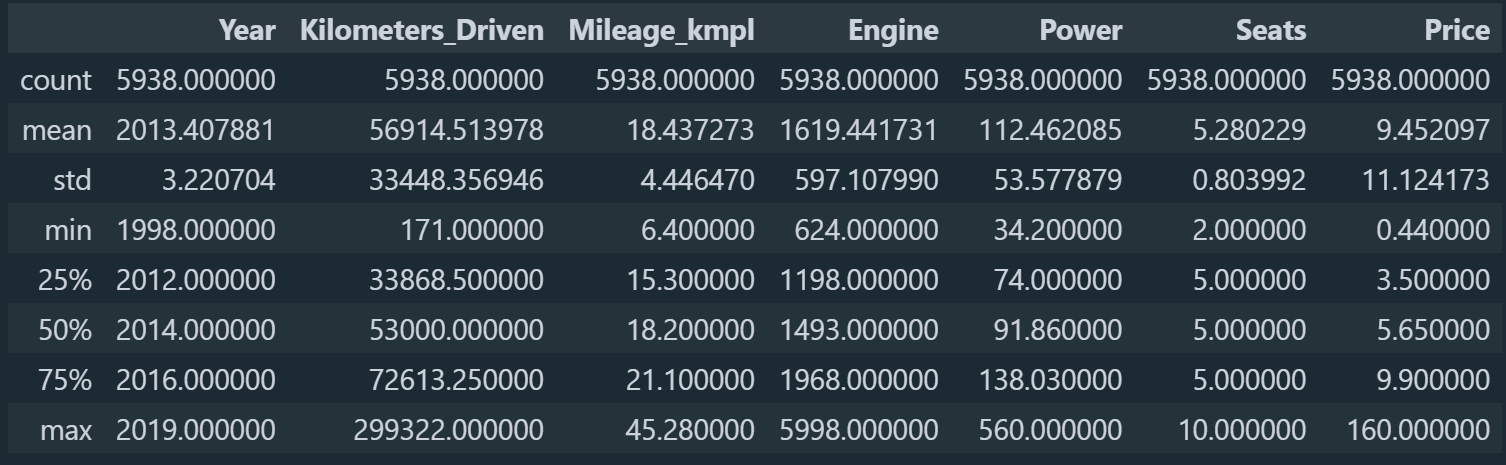
Μπορούμε να δούμε και στο διάγραμμα ότι υπάρχουν κάποιες λίγες ακραίες τιμές, τις οποίες μπορούμε αν θέλουμε να διαγράψουμε. Επίσης κάτι άλλο που φαίνεται στον πίνακα με τα στατιστικά στοιχεία είναι ότι κάποια αυτοκίνητα έχουν 0 κατανάλωση καυσίμου κάτι το οποίο είναι λάθος οπότε θα τα διαγράψουμε και αυτά.
Ας ξαναδούμε τα στατιστικά στοιχεία του πίνακα για να δούμε ότι όντως διορθώθηκε το πρόβλημα.
df.describe()
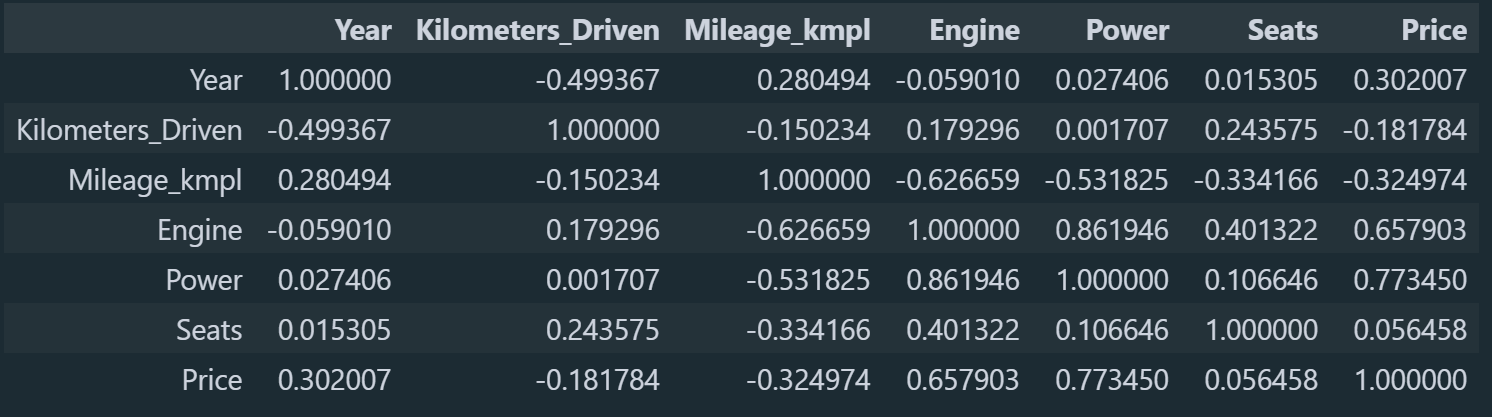
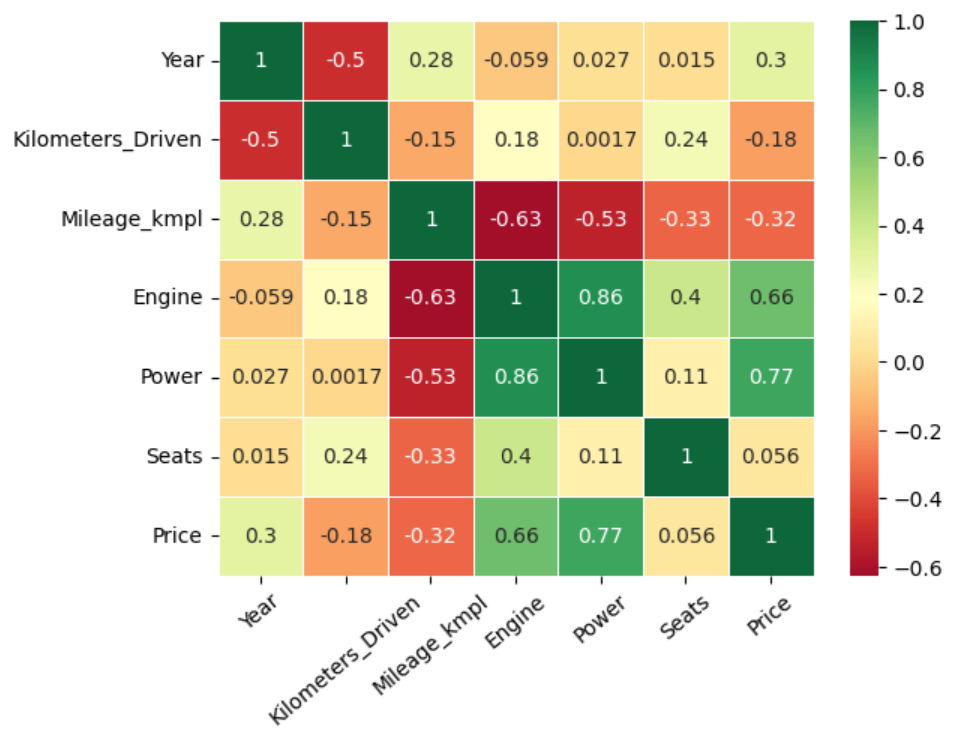
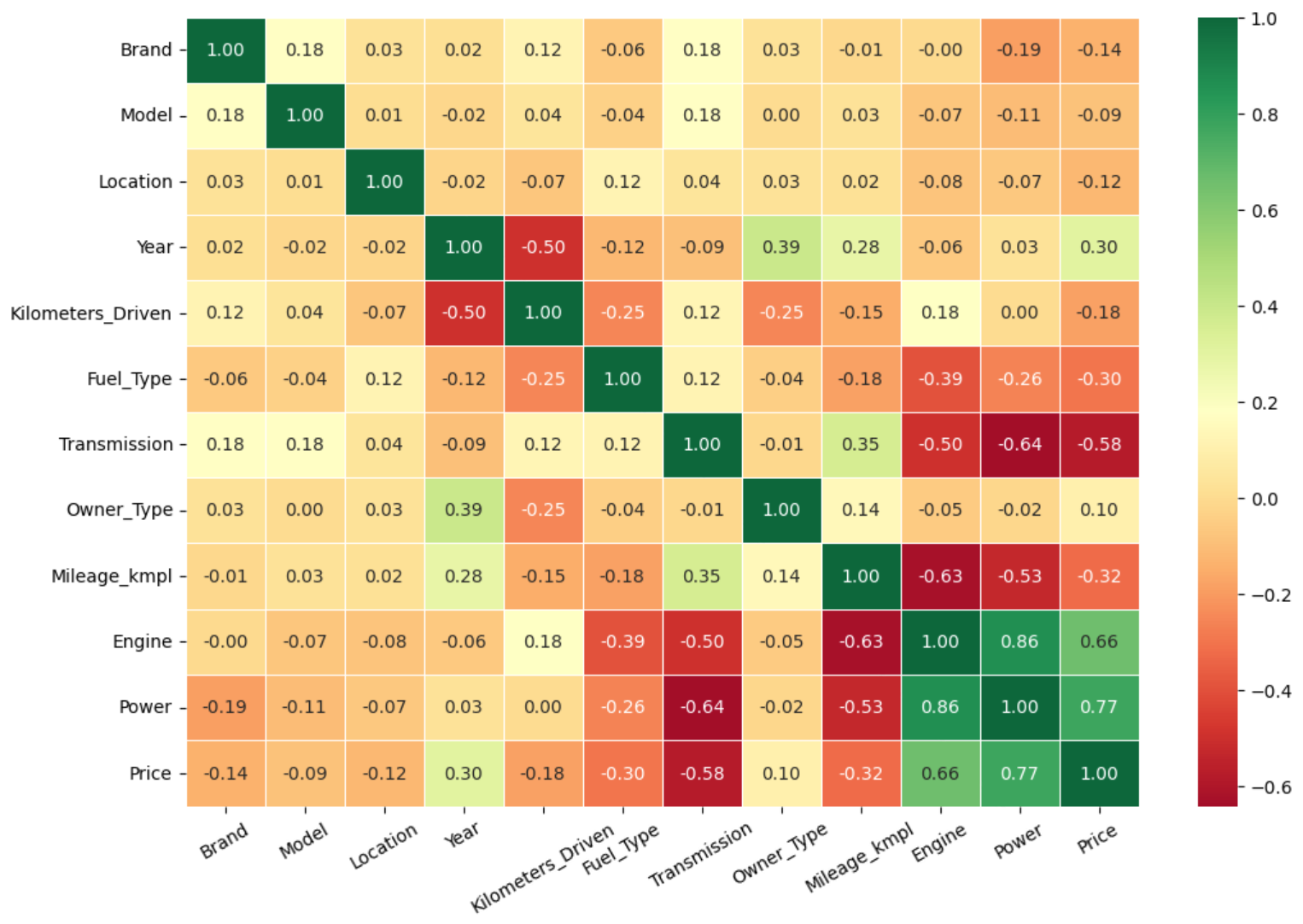
Κάτι άλλο που μπορούμε να δούμε είναι οι συσχετίσεις ανάμεσα στις στήλες, δηλαδή αν μεταβληθεί μία στήλη κατά μία μονάδα πώς μεταβάλεται μία άλλη σε σύγκριση με αυτή.
df.corr()
Επειδή το να βλέπουμε τόσα ΄πολλά νούμερα είναι λίγο μπέρδεμα, ας φτιάξουμε ένα διάγραμμα με τις συσχετίσεις.
Έτσι μπορούμε να δούμε λίγο καλύτερα τις συσχετίσεις μεταξύ των στηλών. Η στήλη που μας ενδιαφέρει περισσότερο είναι η στήλη της τιμής μιας και αυτή θέλουμε να προβλέψουμε. Βλέπουμε πως την μεγαλύτερη συσχέτιση με την τιμή την έχει η στήλη με τα άλογα του αυτοκινήτου. Δηλαδή όσο πιο πολλά άλογα έχει ένα αυτοκίνητο τόσο πιο ακριβό θα είναι, κάτι που ακούγεται και λογικό. Η στήλη που φαίνεται ότι δεν έχει καθόλου συσχέτιση με την τιμή είναι ο αριθμός των θέσεων του αυτοκινήτου και γι αυτό το λόγο αν θέλουμε μπορούμε να την διαγράψουμε.
df.drop(columns='Seats', inplace=True)
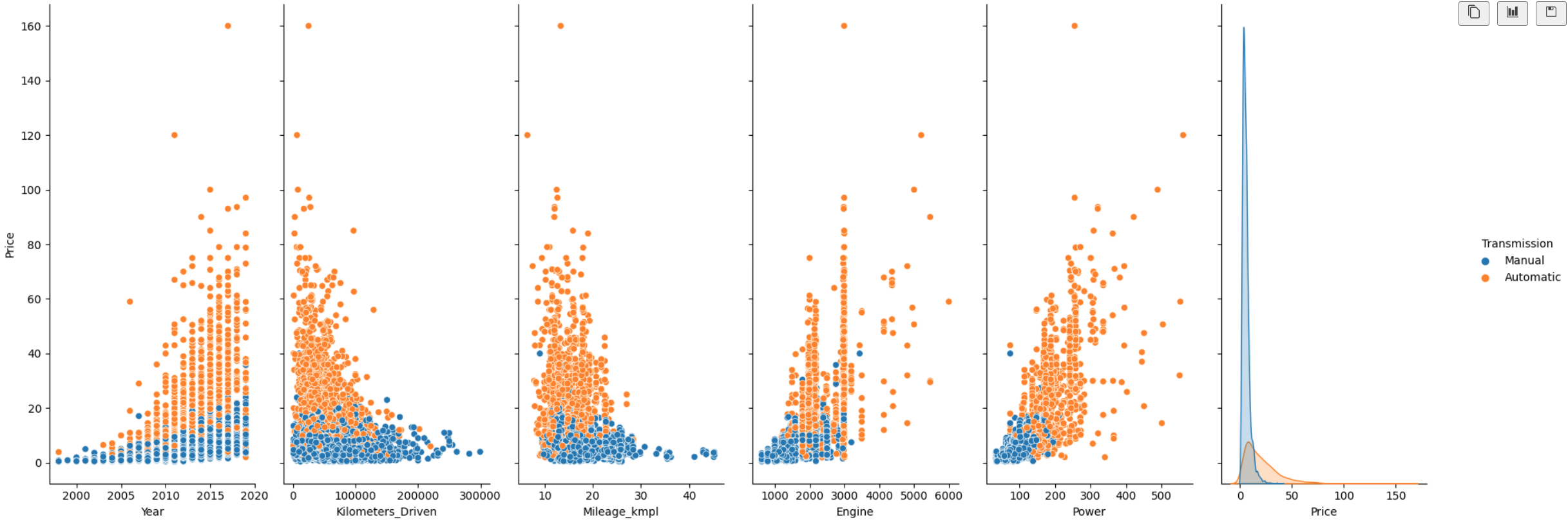
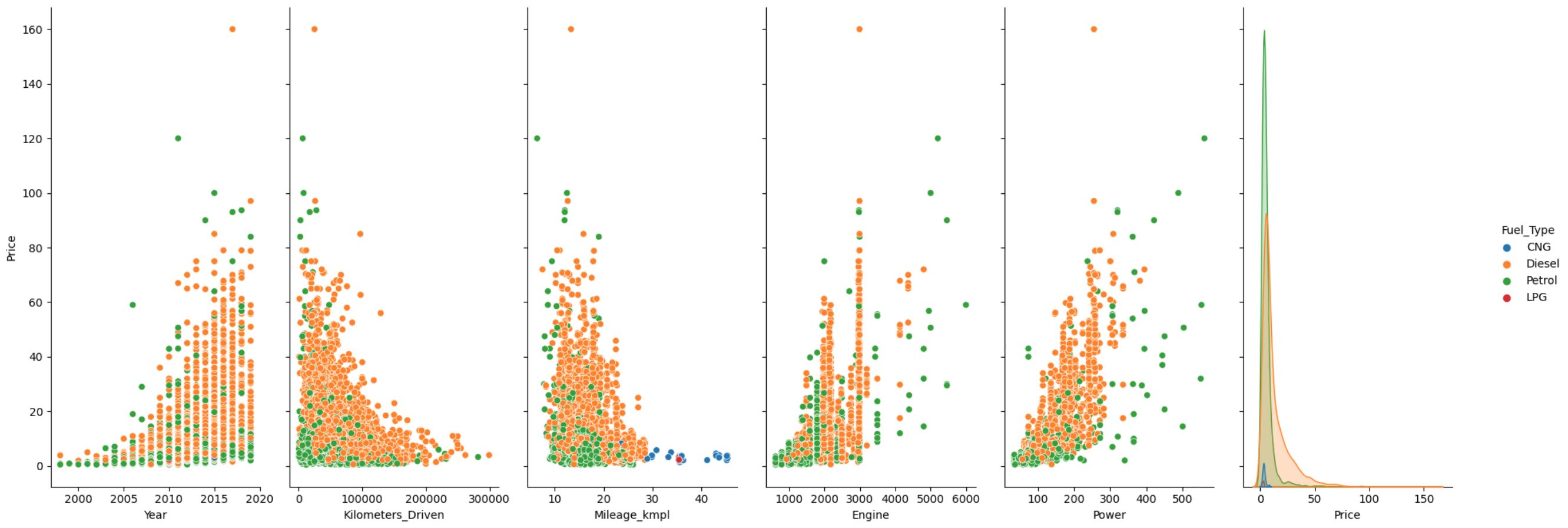
Μπορούμε επίσης να δούμε και ένα πιο αναλυτικό διάγραμμα της τιμής με κάθε μία στήλη. Θα χωρίσουμε επίσης τις τιμές ανάλογα με το είδος του κιβωτίου ταχυτήτων του αυτοκινήτου.
p = sns.pairplot(df,
y_vars='Price',
hue='Transmission')
p.fig.set_figheight(8)
p.fig.set_figwidth(20);
Αυτό που παρατηρούμε είναι ότι η τιμή αυξάνεται με τα χρόνια και ότι το αυτόματο κιβώτιο ταχυτήτων είναι πιο ακριβό από το χειροκίνητο. Επίσης φαίνεται τα αυτοκίνητα με χειροκίνητο κιβώτιο να έχουν περισσότερα χιλιόμετρα. Όσον αφορά την κατανάλωση καυσίμου τα χειροκίνητα κιβώτια φαίνεται να είναι πιο οικονομικά καθώς βγάζουν περισσότερα χιλιόμετρα ανά λίτρο καυσίμου. Αυτό ίσως να οφείλεται όπως βλέπουμε και στα δύο επόμενα διαγράμματα στο ότι τα αυτοκίνητα με αυτόματο κιβώτιο έχουν περισσότερα κυβικά και άλογα.
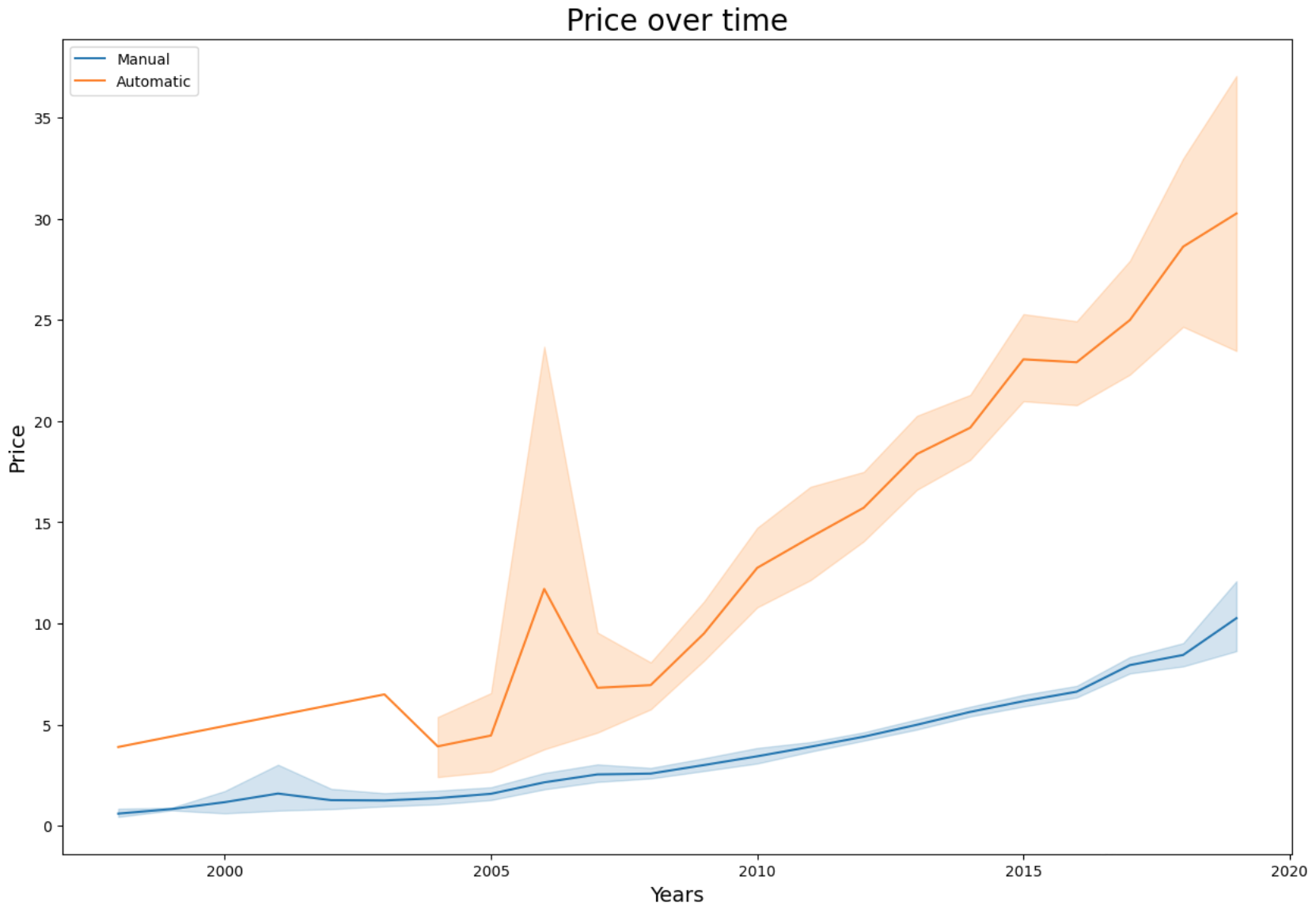
Επειδή πολλές φορές ένα διάγραμμα μπορεί να μας μπερδέψει ας δούμε τα συμπεράσματα που εξάγαμε και με νούμερα. Για να τα υπολογίσουμε θα πρέπει να επιλέξουμε τις στήλες που θέλουμε, να ομαδοποιήσουμε τις τιμές με βάση το είδος του κιβωτίου ταχυτήτων και στην συνέχεια μέσω της μεθόδου .agg() να υπολογίσουμε τον μέσο όρο των υπόλοιπων στηλών.
Εδώ φαίνεται πιο ξεκάθαρα ότι η τιμή των αυτοκινήτων αυξάνεται με τα χρόνια και ότι τα αυτοκίνητα με αυτόματο κιβώτιο είναι πιο ακριβά.
Ας ξαναδούμε λίγο τα δύο τελευταία διαγράμματα αλλά αυτή την φορά ας χωρίσουμε τις τιμές ανάλογα με το είδος καυσίμου.
p = sns.pairplot(df,
y_vars='Price',
hue='Fuel_Type')
p.fig.set_figheight(8)
p.fig.set_figwidth(20);
Στο πρώτο διάγραμμα φαίνεται τα αυτοκίνητα με βενζίνη να είναι πιο ακριβά σε σχέση με τα αυτοκίνητα με πετρέλαιο. Στο δεύτερο αν και όχι τόσο ξεκάθαρα φαίνεται ότι τα αυτοκίνητα με βενζίνη έχουν περισσότερα χιλιόμετρα. Όσον αφορά την οικονομία καυσίμου φαίνεται ξεκάθαρα ότι τα αυτοκίνητα με το CNG είναι τα πιο οικονομικά. Τέλος, για τα κυβικά και τα άλογα φαίνεται τα αυτοκίνητα με πετρέλαιο να έχουν τα περισσότερα.
Όπως και πριν ας το δούμε και με νούμερα για να είμαστε σίγουροι.
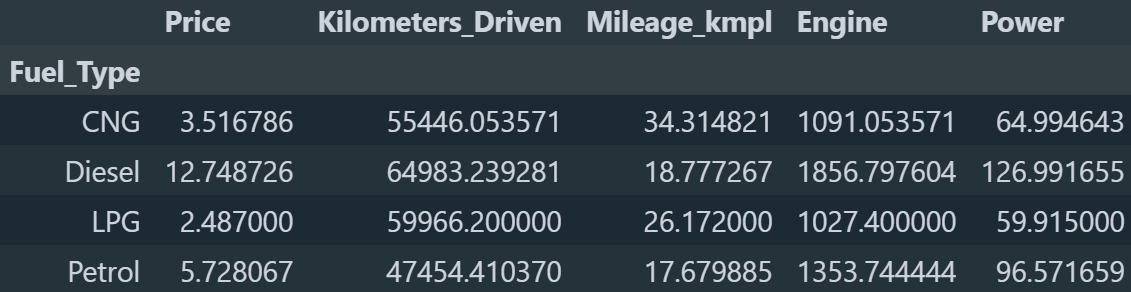
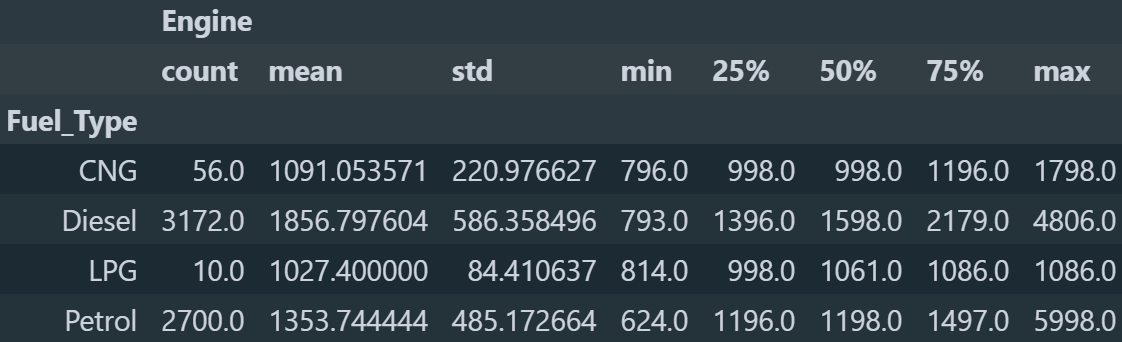
Ενώ στα πρώτα τρία διαγράμματα ήμασταν σωστοί, στα δύο τελευταία φαίνεται ότι τα αυτοκίνητα με βενζίνη έχουν περισσότερα κυβικά και άλογα κατα μέσο όρο. Λογικά το λάθος που κάναμε ήταν ότι είδαμε στο διάγραμμα κάποιες μεγάλες ακραίες τιμές και βγάλαμε από εκεί το συμπέρασμα για τον μέσο όρο. Αλλά για να μην υποθέτουμε ας το δούμε πιο λεπτομερώς. Θα ομαδοποιήσουμε πάλι τις τιμές με βάση τον τύπο καυσίμο αλλά στην συνέχεια αντί για την μέθοδο .agg() θα καλέσουμε την μέθοδο .describe(). *Επειδή αν δούμε όλες τις στήλες ο πίνακας θα βγει τεράστιος θα δούμε μόνο για την στήλη Engine.
Αυτό που υποθέσαμε τελικά ήταν σωστό, γιατί αν δούμε το 75% των παρατηρήσεων, τα κυβικά στα αυτοκίνητα με βενζίνη (2179cc) είναι περισσότερα από τα κυβικά με το πετρέλαιο (1479cc). Ενώ αν δούμε τα μέγιστα κυβικά, τα κυβικά των αυτοκινήτων με πετρελαίο (5998cc) είναι περισσότερα από τα κυβικά στα αυτοκίνητα με βενζίνη (4806cc).
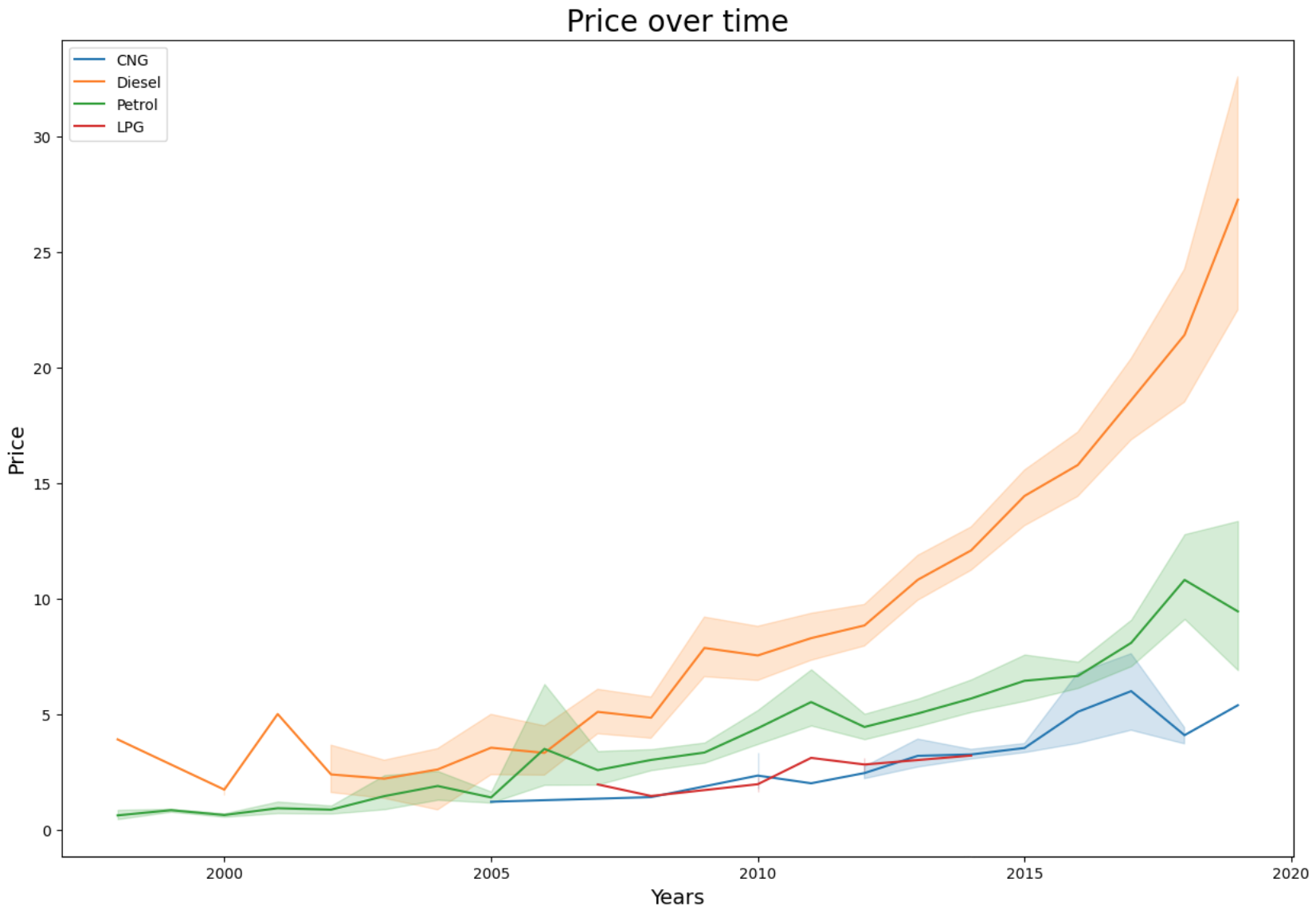
Τέλος, ας δούμε πάλι λεπτομερώς πως κινείται η τιμή των αυτοκινήτων με τα χρόνια αλλά τώρα θα τα χωρίσουμε ανάλογα με τον τύπο καυσίμου.
Εδώ μπορούμε να παρατηρήσουμε πιο ξεκάθαρα ότι τα πιο ακριβά αυτοκίνητα είναι αυτά με βενζίνη.
Data Pre-Processing
Ο πίνακάς μας έχει ακόμα στήλες που δεν είναι αριθμοί, οπότε θα πρέπει να τις μετατρέψουμε και αυτές σε αριθμούς. Θα ξεκινήσουμε με την στήλη Owner_Type, σε αυτή την στήλη θα κάνουμε μόνοι μας την αντιστοίχηση από τις λέξεις στους αριθμούς. Ο λόγος είναι γιατί η σειρά που θα γράψουμε τις τιμές πάιζει ρόλο. Δηλαδή το πρώτο χέρι είναι καλύτερο από το τρίτο κλπ. Αρχικά θα φτιάξουμε ένα dictionary με τις λέξεις και τα νούμερα και στην συνέχεια με την μέθοδο map() θα επεξεργαστούμε την στήλη μας για να την μετατρέψουμε σε αριθμούς.
Τις υπόλοιπες σειρές θα τις μετατρέψουμε αυτόματα χρησιμοποιόντας την μέθοδο .categorical() από την βιβλιοθήκη της Pandas για να μετατρέψουμε όλες τις τιμές σε κατηγορίες και στην συνέχεια προσθέτοντας το attribute .codes θα μετατρέψουμε τις κατηγορίες σε αριθμούς.
categories = ['Brand', 'Model', 'Location', 'Year', 'Fuel_Type', 'Transmission']
for column, row in df.items():
if column in categories:
df[column] = pd.Categorical(row).codes
Ας δούμε πώς έχει διαμορφωθεί ο τελικός πίνακας.
df.head()
Τώρα που όλες οι στήλες μας είναι με αριθμούς ας ξαναδούμε τις συσχετίσεις μεταξύ των στηλών.
Από τις νέες στήλες μπορούμε να δούμε ότι την μεγαλύτερη συσχέτιση (αρνητική) με την τιμή την έχει η στήλη transmission. Η συσχέτιση είναι αρνητική γιατί η τιμή Automatic έχει τον αριθμό 0 και η τιμή Manual έχει τον αριθμό 1. Οπότε όταν πάμε από ένα αυτόματο σε ένα χειροκίνητο ενώ ο αριθμός αυξάνεται (από το 0 στο 1) η τιμή μειώνεται, μιας και τα χειροκίνητα είναι φθηνότερα. * Οι συσχετίσεις μετράνε γραμμικές τιμές, οπότε στήλες όπως το μοντέλο, η τοποθεσία κλπ δεν θα πρέπει να τις λαμβάνουμε και πολύ υπόψη.
Modelling
Το πρώτο πράγμα που πρέπει να κάνουμε είναι να χωρίσουμε τον πίνακα στα δύο. Το ένα μέρος είναι τα δεδομένα που θα είναι γνωστά και το άλλο μέρος θα είναι η στήλη που θέλουμε να προβλέψουμε, η στήλη της τιμής στην συγκεκριμένη περίπτωση. Οπότε ο ένας πίνακας θα περιέχει την τιμή και ο άλλος τις υπόλοιπες στήλες.
X = df.drop(columns='Price')
y = df['Price']
Η Γραμμική παλινδρόμηση (Linear Regression) είναι της μορφής:
Η εξίσωσή μας θα έχει τόσα x όσες και οι στήλες του πίνακα x.
Οπότε ουσιαστικά εμείς δίνουμε στον υπολογιστή τα x και αυτός δοκιμάζει διάφορες τιμές στα θ για να προβλέψει το y. Όσο κάνουμε training τον αλγόριθμο κάθε φορά αυτός θα δίνει μία τιμή σε κάθε θ και θα υπολογίζει με αυτά την τιμή του y, μετά θα συγκρίνει την τιμή του y που προέβλεψε με την πραγματική τιμή του y και ανάλογα το πόσο λάθος είναι θα αλλάζει και τις τιμές των θ μέχρι να φτάσει όσο πιο κοντά γίνεται στην πραγματική τιμή του y. Οι φορές που θα τρέξει ένας αλγόριθμος εξαρτάται είτε από τον ίδιο τον αλγόριθμο είτε από εμάς, μπορούμε δηλαδή να τον βάλουμε να τρέξει όσες φορές θέλουμε για να μπορέσει να φτάσει όσο πιο κοντά στο πραγματικό y γίνεται.
Γιατί να μην το κάνουμε:
Όσες περισσότερες φορές τρέξει ένας αλγόριθμος τόσο περισσότερη ώρα θα πάρει. Μπορεί να μιλάμε για λεπτά μέχρι μέρες ανάλογα με τον αλγόριθμο, τις στήλες και τις γραμμές του πίνακα.
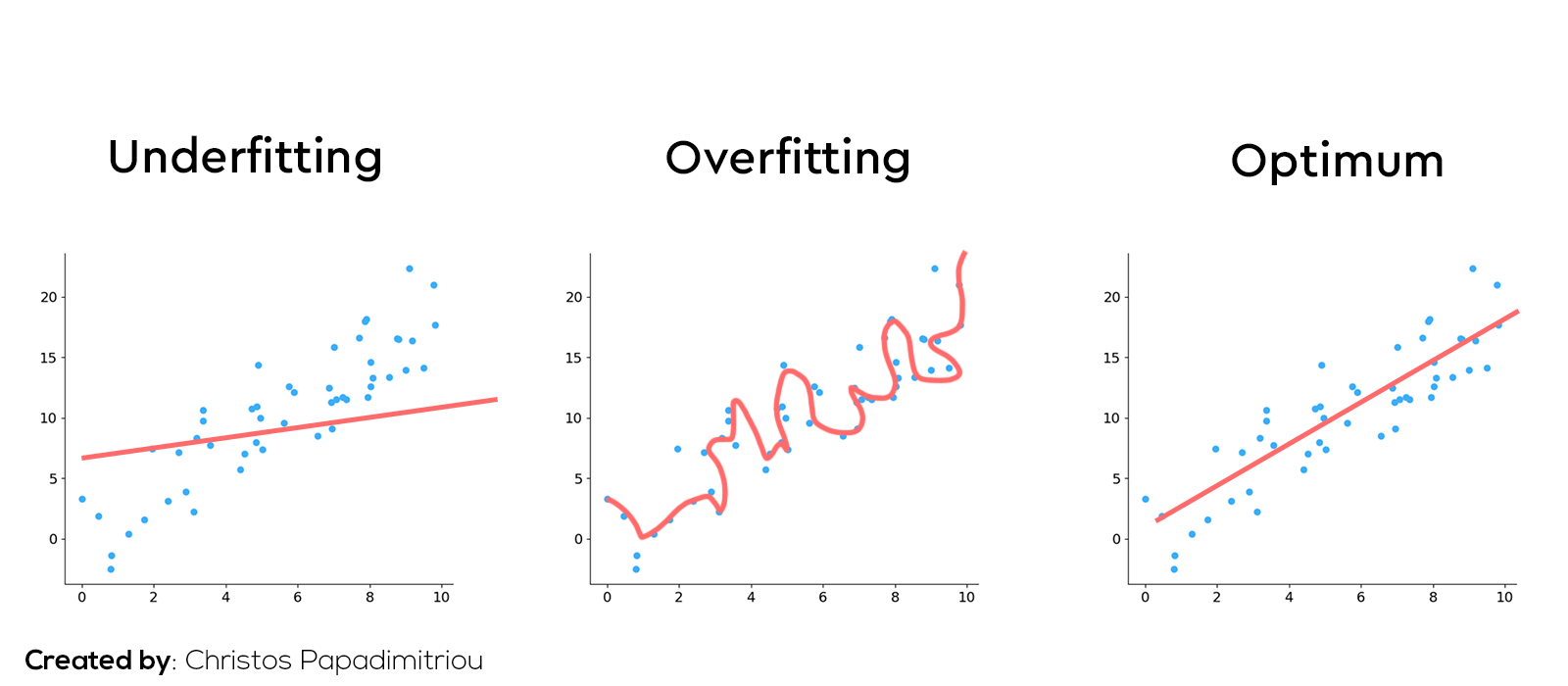
Ένα άλλο πρόβλημα είναι η περίπτωση του overfitting. Να μάθει δηλαδή ο αλγόριθμος πολύ καλά τα δεδομένα του training αλλά να τα πάει χάλια στα δεδομένα του testing. Εμείς θέλουμε ο αλγόριθμος να βρει κάποια μοτίβα μέσα στα δεδομένα τα οποία θα μπορεί να χρησιμοποιεί σε όποιο πίνακα και να τον τρέξουμε. Με το overfitting ουσιαστικά μαθένει απ’ έξω όλες τις μικρές λεπτομέρειες του training πίνακα οι οποίες δεν ισχύουν γενικά.
Όμως δεν πρέπει να τρέξουμε τον αλγόριθμο και πολύ λίγες φορές γιατί μπορεί να αντιμετωπίσουμε του πρόβλημα του Underfitting, να έχει δηλαδή ο αλγόριθμός χαμηλό accuracy και στον training και στον testing πίνακα. Πρέπει δηλαδή να βρούμε μία ισσοροπία στο πόσες φορές θα τρέξουμε έναν αλγόριθμο.
Πόσες φορές όμως πρέπει να τον τρέξουμε? Δεν υπάρχει κάποια στάνταρ απάντηση, εξάρτάται από τα δεδομένα που έχουμε κάθε φορά και από τον αλγόριθμο που θα χρησιμοποιήσουμε. Δοκιμάζουμε διάφορα νούμερα και βλέπουμε κάθε φορά.
Παρακάτω μπορούμε να δούμε σε διάγραμμα ένα γενικό παράδειγμα με το πως είναι μία underfit και μία overfit εκτίμηση αλλά και η βέλτιστη.
*Η εκτίμηση στο overfitting δεν είναι γραμμική.
Γράφουμε τόση ώρα για train και test data, πάμε λοιπόν να χωρίσουμε τον πίνακα. Συνήθως κρατάμε το μεγαλύτερο ποσοστό για το training για να μπορέσει να μάθει το μοντέλο μας τα μοτίβα και λιγότερα για το testing. Ένα σύνηθες ποσοστό είναι 80% για training και 20% για testing. Αφού έχουμε χωρίσει τον αρχικό πίνακα ήδη στα δύο τώρα σημαίνει ότι θα φτάσουμε να έχουμε 4 πίνακες, τους οποίους θα ονομάσουμε X_train, X_test, y_train, y_test. Ο χωρισμός γίνεται πολύ εύκολα με την βοήθεια του Scikit-Learn.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
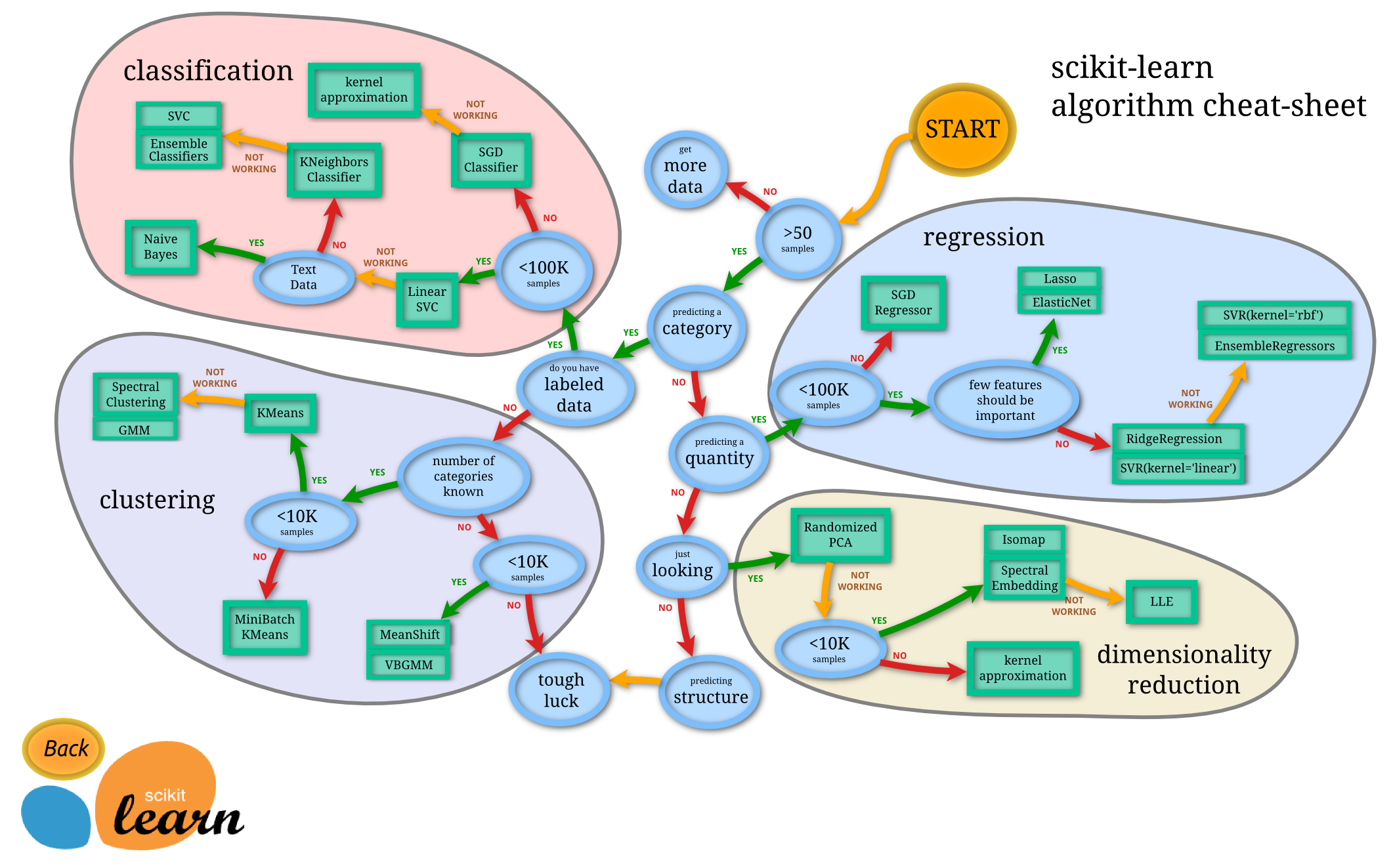
Μετά και από αυτόν τον χωρισμό είμαστε έτοιμοι να βάλουμε τους πίνακες στον αλγόριθμό μας και να τον κάνουμε training, το μόνο που λείπει είναι να διαλέξουμε ποιον αλγόριθμο θέλουμε. Το Scikit-Learn μας παρέχει έναν χάρτη ο οποίος μας βοηθάει να διαλέξουμε έναν αλγόριθμο ανάλογα με τα δεδομένα που έχουμε.
Photo by: scikit-learn.org
Θα χρησιμοποιήσουμε τον αλγόριθμο LinearRegression από το Scikit-Learn. H βιβλιοήθηκη της Scikit-Learn μας το κάνει πολύ εύκολο να κάνουμε train τον αλγοριθμό μας και μετά να τον τεστάρουμε.
Το μόνο που έχουμε να κάνουμε είναι:
Nα καλέσουμε τον αλγόριθμο LinearRegression
Να τον κάνουμε training, καλώντας την μέθοδο .fit() και μέσα της να περάσουμε της πίνακες X_train και y_train
Και τέλος για να δούμε το accuracy του αλγορίθμου μας να καλέσουμε την μέθοδο .score() που μέσα θα περάσουμε τους πίνακες X_test, y_test.
Αν θέλουμε μπορούμε να καλέσουμε και την μέθοδο .score() στον πίνακα του training για να δούμε και το accuracy σε αυτόν. Σε αυτή την περίπτωση και στο training και στο testing το accuracy ειναι περίπου 70%. *Αν τρέξετε και εσείς ακιβώς τον ίδιο κώδικα τότε θα πρέπει να έχετε ένα accuracy κοντά στο 70%, κάθε φορά που θα τρέχετε τον κώδικα όμως θα βλέπετε μια διαφορά στο ακριβές αποτέλεσμα η οποία είναι λογική, οπότε αν δεν έχετε ακριβώς τα ίδια αποτελέσματα με τα δικά μου δεν χρειάζεται να ανυσηχείται εκτός και αν έχουν πολύ μεγάλη διαφορά.
Πώς μπορούμε να βελτιώσουμε το accuracy του μοντέλου μας;
Θα μπορούσαμε να αλλάξουμε τις παραμέτρους του, αλλά αυτό δεν θα βελτιώνε και ιδιαίτερα το accuracy μας σε αυτήν την περίπτωση. Εάν πάμε πιο πάνω και δούμε τα διαγράμματα scatterplot και παρατηρήσουμε τις τιμές θα δούμε ότι είναι δύσκολο να εκτιμήσουμε την τιμή με μεγάλη ακρίβεια με μία γραμμική παλινδρόμηση. Οπότε αυτό που θα κάνουμε είναι να χρησιμοποιήσουμε έναν μη-γραμμικό αλγόριθμο για την εκτίμηση της τιμής και συγκεκριμένα τον αλγόριθμο Gradient Boosting Regressor.
Όσον αφορά τον κώδικα δεν αλλάζει κάτι δραματικά, απλά εκεί που γράφαμε LinearRegression θα γράψουμε GradientBoostingRegressor.
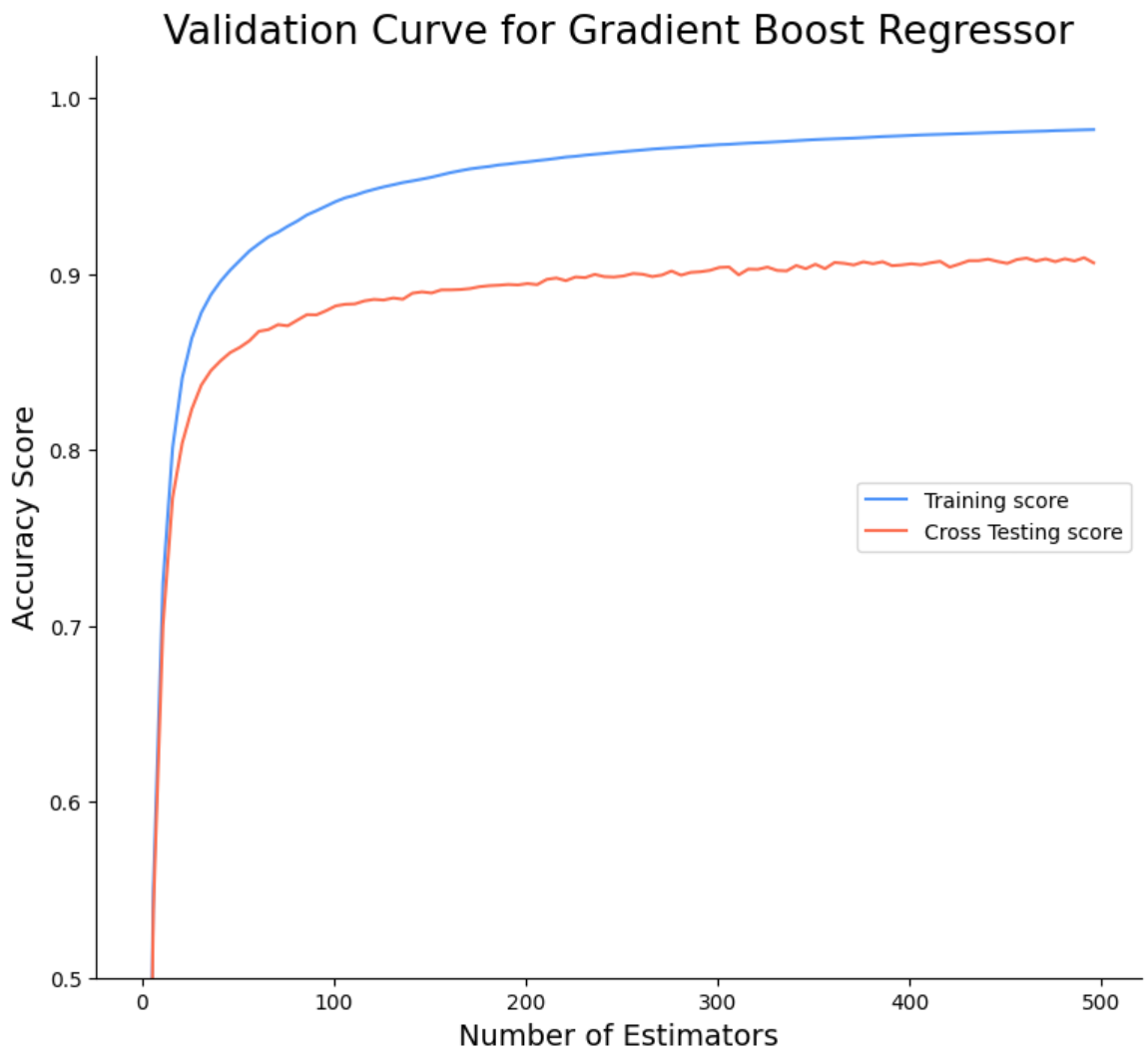
Αλλάζοντας απλά τον αλγόριθμο καταφέραμε να πάμε το accuracy στον πίνακα testing από το 70% στο 90%. Κάθε αλγόριθμος έχει και διάφορους παραμέτρους που μπορούμε να αλλάξουμε, δεν θα κάτσουμε σε αυτό το μάθημα να ασχοληθούμε με όλους αλλά ας δούμε έναν, το ‘n_estimators’. Αυτή η παράμετρος δείχνει τον αριθμό τον estimators που χρησιμοποιεί ο αλγόριθμος, το default είναι 100, ας δοκιμάσουμε εμείς 1000.
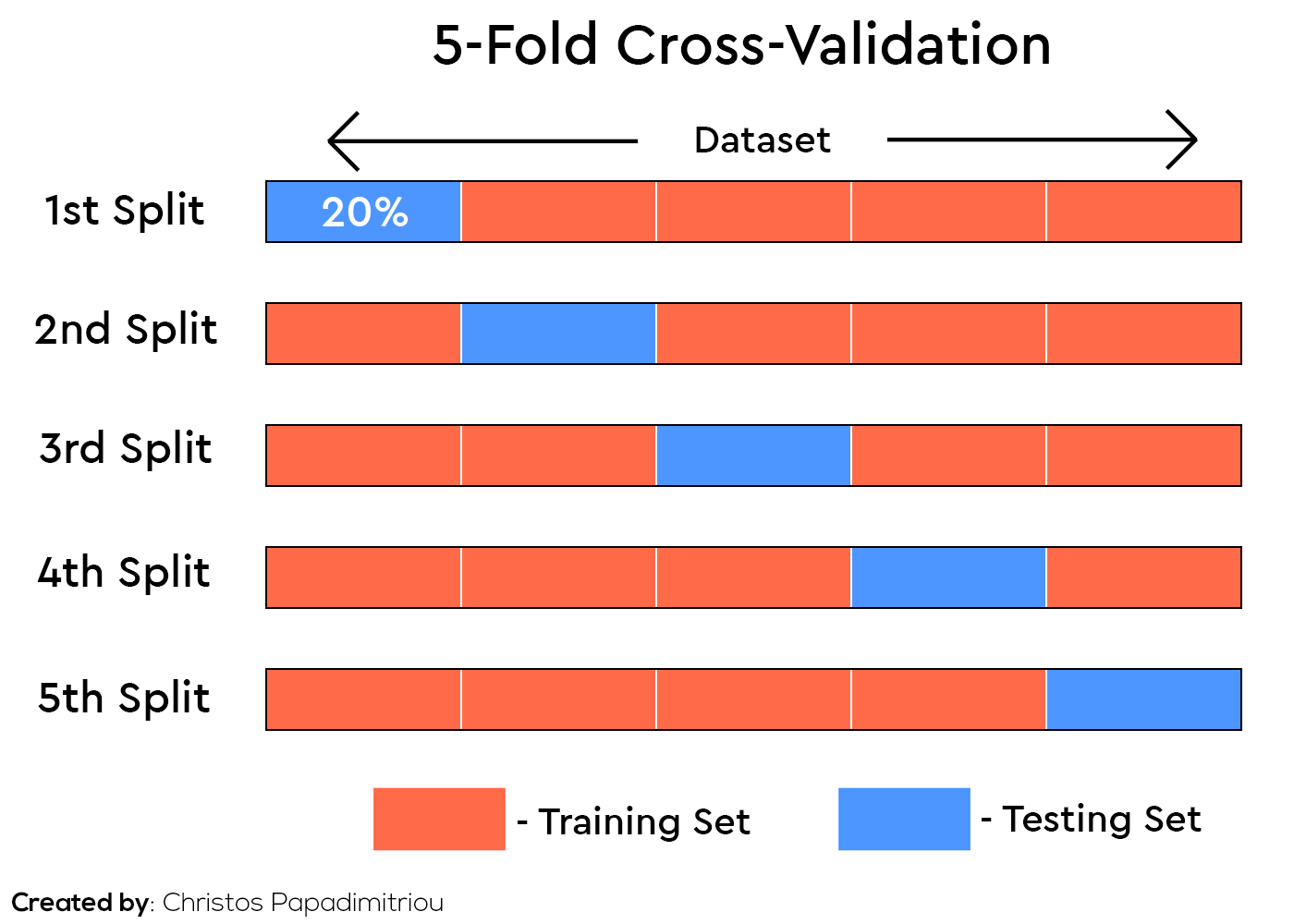
Αυτό που παρατηρούμε είναι ότι αυξήθηκε κατα 4% το testing accuracy, από το 90% στο 94%. Το μοντέλο μας πλέον έχει ένα πάρα πολύ καλό accuracy. Αν θέλουμε μπορούμε να φτιάξουμε ένα διάγραμμα που να μας δείχνει το accuracy για κάθε αριθμό από estimators. Πριν πάμε όμως να δούμε το διάγραμμα, ας εισάγουμε μία καινούργια έννοια, το cross validation. Μέχρι τώρα όταν θέλαμε να κάνουμε training και testing τον αλγοριθμό μας χωρίζαμε στα 2 τα δεδομένα μας σε 80% ο ένας πίνακας και σε 20% ο άλλος και τρέχαμε τον αλγόριθμο μας. Τι θα γινόταν όμως αν το κομμάτι που είχαμε διαλέξει για testing τύχαινε να έχει κάποιες εύκολες τιμές για πρόβλεψη ή το αντίθετο; Τότε το ποσοστό ακρίβειας του αλγορίθμου μας δεν θα ήταν και τόσο αντιπροσωπευτικό. Για να το λύσουμε αυτό το πρόβλημα μπορούμε να χρησιμοποιήσουμε μία μέθοδο που λέγεται cross-validation, ουσιαστικά αυτό που κάνει είναι να χωρίζει πάλι τα δεδομένα μας σε δύο πίνακες αλλά σε διαφορετικά κομμάτια κάθε φορά και στο τέλος βγάζει έναν μέσο όρο από το accuracy αυτών. Ας το δούμε σε ένα διάγραμμα για να το καταλάβουμε καλύτερα.
Στην παραπάνω φωτογραφία βλέπουμε ότι χωρίσαμε πάλι τα δεδομένα σε 80-20% αλλά πήραμε κάθε φορά διαφορετικό κομμάτι από τον πίνακα για το training και το testing. Στην συγκεκριμένη περίπτωση δοκιμάσαμε 5 διαφορετικά κομμάτια, αλλά μπορούμε να το χωρίσουμε όσες φορές θέλουμε. Ένας μεγαλύτερος αριθμός θα μας δώσει ένα πιο ακριβή accuracy αλλά μιας και θα πρέπει να τρέχουμε τον αλγόριθμο περισσότερες φορές θα πάρει και περισσότερο χρόνο. Οπότε πρέπει να βρούμε μία μέση λύση, ένας αριθμός από το 3 μέχρι το 5 συνήθως είναι αρκετός. Για να σχεδιάσουμε το accuracy γαι κάθε estimator του αλγορίθμου μας θα χρειαστεί να κάνουμε import την κλάση validation_curve από το Scikit-Learn και θα χρειαστούμε και το Numpy.
import numpy as np
from sklearn.model_selection import validation_curve
Η κλάση validation_curve παίρνει σαν παράμετρους:
Τον αλγόριθμό μας
Τους πίνακες Χ και y (πριν τους χωρίσουμε σε train και test)
Την παράμετρο που θέλουμε να τεστάρουμε, σε αυτή την περίπτωση το ‘n_estimators’
Τις τιμές που θέλουμε να δοκιμάσουμε σε αυτή την παράμετρο
Τον αριθμό για το cross-validation
Τέλος, τον αριθμό των πυρήνων του επεξεργαστή μας που θέλουμε να χρησιμοποιήσουμε για τον υπολογισμό αυτό
Και μας επιστρέφει το accuracy για το training και το testing.
Αρχικά επειδή θέλουμε να δοκιμάσουμε πολλές τιμές για τον αριθμό των estimators και επειδή είναι κουραστικό να γράφουμε έναν έναν αριθμό με το χέρι θα χρησιμοποιήσουμε το Numpy. Θέλουμε να υπολογίσουμε από 1 μέχρι 500 estimators, επειδή όμως είναι πολλές οι τιμές και δεν μας ενδιαφέρει και τόσο η μεταβολή του accuracy για κάθε έναν estimator θα φτιάξουμε ένα array από το 1 μέχρι το 500 αλλά θα προσθέτουμε κάθε 5ο αριθμό για να μην έχουμε 500 διαφορετικές περιπτώσεις που θα πρέπει να τρέξουμε τον αλγοριθμό μας και εάν υπολογίσουμε και ότι για κάθε περίπτωση θα το τρέχουμε 5 φορές λόγου του cross-validation, μας βγαίνει ότι θα πρέπει να τρέξουμε τον αλγοριθμό μας 2500 φορές, κάτι που όπως φαντάζεσται θα πάρει αρκετό χρόνο. Για αυτό θα τρέχουμε τον αλγόριθμο κάθε 5 estimators για να το μειώσουμε από 2500 σε 500 φορές.
Στο train_score και test_score ύπαρχουν τα accuracy και για τα 5cross-validation, εμείς όμως θέλουμε ένα accuracy ανά estimator. Για να το κάνουμε αυτό θα χρησιμοποιήσουμε το Numpy και θα βρούμε το μέσο όρο των 5 τιμών.
train = np.mean(train_scores, axis=1)
test = np.mean(test_scores, axis=1)
Αυτό που παρατηρούμε είναι ότι το accuracy αυξάνεται απότομα μέχρι τους πρώτους 50 estimators και μετά συνεχίζει να αυξάνεται με πολύ μικρό ρυθμό. Επίσης βλέπουμε ότι το testing accuracy είναι χαμηλότερο από το training κάτι που αν είναι μικρή η διαφορά είναι το φυσιολογικό. Δεν περιμένουμε δηλαδή το testing accuracy να είναι μεγαλύτερο από το training accuracy. Ούτε όμως και η διαφορά του training με του testing accuracy να είναι τεράστια.
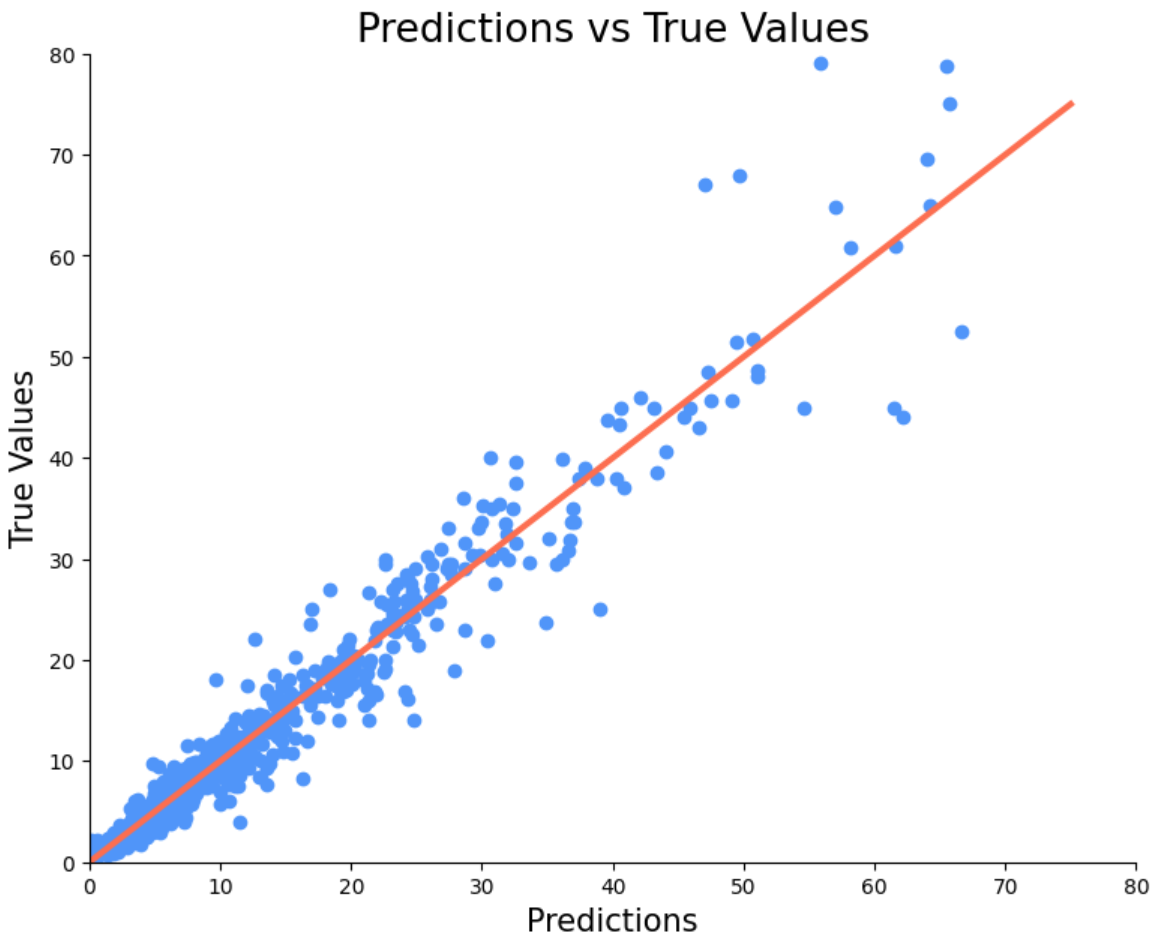
Για να υπολογίσουμε το accuracy ο αλγόριθμός μας κάνει προβλέψεις στην τιμή και μετά συγκρίνει την τιμή που προέβλεψε με την πραγματική και βγάζει το ποσοστό ακρίβειας. Τι γίνεται όμως αν θέλουμε να δούμε τις προβλεψεις του αλγορίθμου μας; Τότε πολύ απλά αντί να καλέσουμε την μέθοδο .score(X_test, y_test) καλούμε την μέθοδο .predict(X_test). Πάμε να δούμε σε ένα διάγραμμα τις προβλέψεις του μοντέλου μας σε σχέση με τις πραγματικές τιμές.
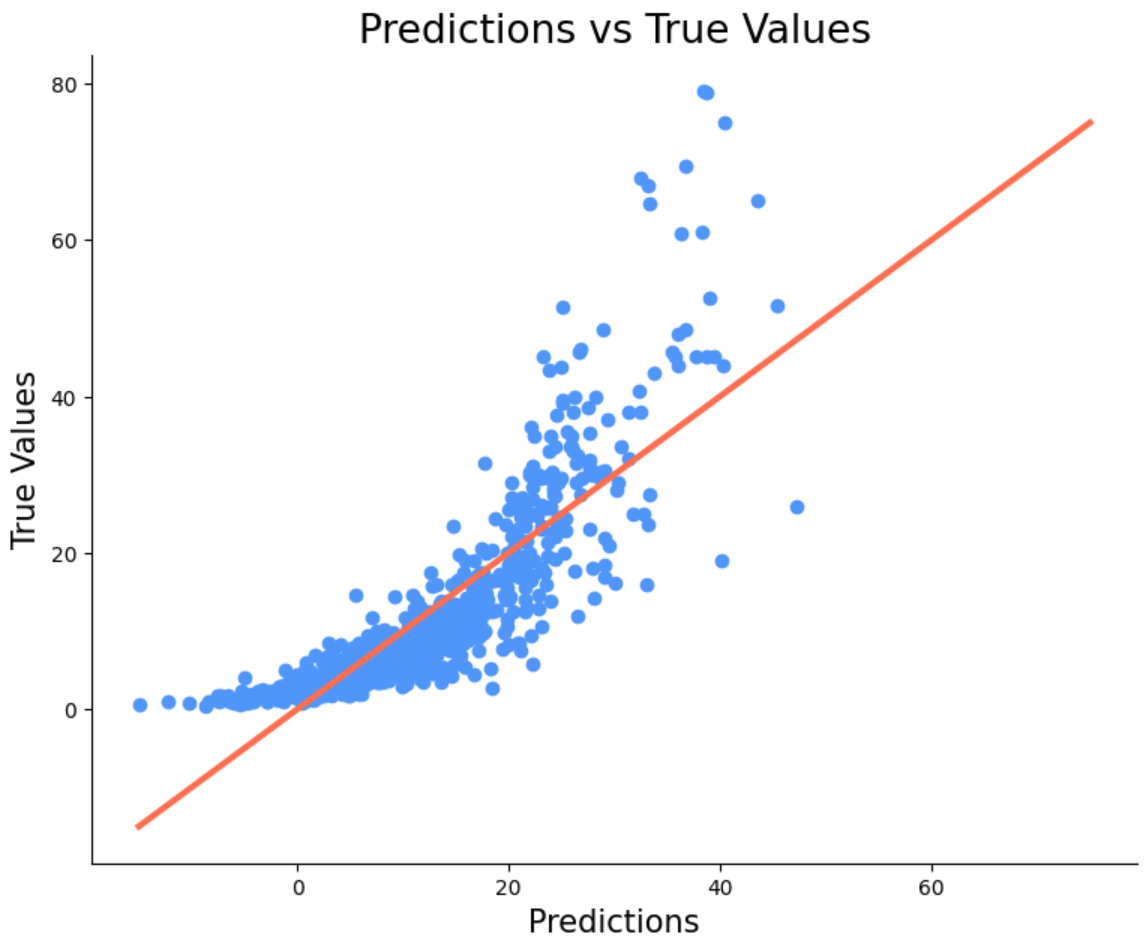
Αν το μοντέλο μας είχε 100% accuracy τότε όλες οι τιμές θα ήταν πάνω στη κόκκινη γραμμή. Βλέπουμε πάντως ότι είναι πολύ κοντά οι προβλέψεις μας. Επίσης αυτό που παρατηρούμε είναι ότι οι προβλέψεις μας είναι πιο σωστές όταν η τιμή είναι μικρή. Αυτό συμβαίνει γιατί άμα παρατηρήσετε στις χαμηλές τιμές έχουμε περισσότερα δεδομένα σε σχέση με τα αυτοκίνητα που είναι ακριβά. Και συνήθως όσο πιο πολλά δεδομένα έχουμε τόσο πιο ακριβές είναι το μοντέλο μας. Ας δούμε για την σύγκριση και τις προβλέψεις του πρώτου μας μοντέλου το οποίο ήταν γραμμικό.
Όπως θα περιμέναμε οι παρατηρήσεις είναι αρκετά μακριά από την κόκκινη γραμμή η οποία δείχνει το που θα έπρεπε να ήταν οι εκτιμήσεις του μοντέλου μας εάν είχε 100% accuracy.
Και τώρα τι; Αφού φτιάξαμε το μοντέλο μας τώρα μπορούμε να το χρησιμοποιήσουμε για να να προβλεπουμε την τιμή μεταχειρισμένων αυτοκινήτων. Μια εφαρμογή θα μπορούσε να ήταν μία ιστοσελίδα όπου οι ενδιαφερόμενοι θα συμπλήρωναν τα χαρακτηριστικά του αυτοκινήτου τους και ο αλγόριθμός μας θα υπολόγιζε την τιμή του.
Σε αυτό το μάθημα είδαμε από την αρχή έως το τέλος την διαδικασία που πρέπει να κάνουμε για να χρησιμοποιήσουμε έναν αλγόριθμο και να προβλέψουμε μία τιμή. Καλύψαμε τα εντελώς βασικά, μπορείτε ακόμα να δείτε διαφορετικούς αλγόριθμους, να δοκιμάσετε διαφορετικούς παραμέτρους ακόμα και να δοκιμάσετε διαφορετικούς τρόπους με το πως θα μετατρέψετε τα δεδομένα από κείμενο σε αριθμό.
Αν βρήκες ενδιαφέρον αυτό το μάθημα μπορείς να μας κεράσεις έναν καφέ ή να το μοιραστείς με τους φίλους στα social media.