Faker
Η Faker είναι μία βιβλιοθήκη της Python η οποία μας βοηθάει να δημιουργήσουμε τυχαία ψεύτικα δεδομένα.
Ψεύτικα δεδομένα μπορούμε να χρησιμοποιήσουμε για να τεστάρουμε κάποιο πρόγραμμα που έχουμε φτιάξει ή για να γεμίσουμε κάποια βάση δεδομένων.
Εισαγωγή
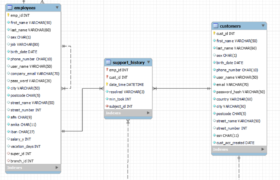
Στο συγκεκριμένο μάθημα θα δημιουργήσουμε δύο πίνακες με ψεύτικα δεδομένα. Ο ένας πίνακας θα αφορά εργαζόμενους και ο δεύτερος τους πελάτες της εταιρείας. Θα υποθέσουμε ότι η εταιρεία είναι μία ελληνική εταιρεία η οποία είναι μία ψηφιακή τράπεζα. Οι υπάλληλοι της θα είναι όλοι από διάφορες πόλεις της Ελλάδας, ενώ οι πελάτες της θα είναι από όλο τον κόσμο.
Τον κώδικα τον τρέχουμε στο VS Code με το plugin Jupyter. Αν δεν θέλετε να μπλέκετε με το να κατεβάζετε προγράμματα μπορείτε να τρέξετε τον κώδικα online στο Google colab, πηγαίνοντας file -> new notebook.
Αρχικά κάνουμε εγκατάσταση την βιβλιοθήκη της Faker.
pip install Faker Ξεκινάμε κάνοντας import την βιβλιοθήκη της Faker και δημιουργούμε ένα object από το class της Faker.
Επίσης θα χρειαστούμε και μια βιβλιοθήκη που ονομάζεται Pandas την οποία θα χρησιμοποιήσουμε μόνο στο τέλος για να δημιουργήσουμε ένα dataframe με τα δεδομένα που θα έχουμε φτιάξει. Επιπλέον θα χρειαστούμε και ένα module της Python που λέγεται random, το οποίο θα το χρησιμοποιήσουμε παράλληλα με το Faker για την δημιουργία τυχαίων δεδομένων. Θα τα κάνουμε και αυτά import στην αρχή.
from faker import Faker
import random
import pandas as pd
fakergr = Faker('el_GR')
faker = Faker() Το Faker υποστηρίζει δεδομένα από πολλές γλώσσες, γι’ αυτό το λόγο θα δημιουργήσουμε δύο Objects. Ένα για ελληνικά δεδομένα και ένα για αγγλικά.
Δημιουργία Ψεύτικων Δεδομένων
Θα ξεκινήσουμε με τα δεδομένα των εργαζομένων πρώτα.
Αρχικά μπορούμε να δημιουργήσουμε τυχαία ονόματα, μικρά και επίθετα αλλά και αντρικά ή/και γυναικεία.
Θα χρησιμοποιήσουμε το ελληνικό object της Faker που φτιάξαμε μιας και όπως είπαμε η εταιρεία είναι ελληνική οπότε θέλουμε ελληνικά ονόματα.
fakergr.first_name_male()
fakergr.last_name_male()
fakergr.first_name_female()
fakergr.last_name_female()
->'Παντελής'
->'Αμπατζιάνης'
->'Σεβαστή'
->'Μηλιάκη' Αφού καλέσουμε το object της Faker στην συνέχεια μπορούμε να καλέσουμε την κάθε μέθοδο ξεχωριστά για το μικρό όνομα και για το επίθετο αλλά και ξεχωριστή μέθοδο για αρσενικό ή θηλυκό όνομα.
Έπειτα θα χρησιμοποιήσουμε το random module για να δημιουργήσουμε το φύλο κάθε εργαζόμενου.
Καλούμε την μέθοδο choices η οποία θα επιλέξει τυχαία ανάμεσα σε ‘Α‘ για αρσενικό και ‘Θ‘ για θηλυκό. Μιας και πρόκειται για εταιρεία τεχνολογίας σε χρηματοοικονομικό τομέα μπορούμε να υποθέσουμε ότι οι άντρες εργαζόμενοι θα είναι περισσότεροι. Για να πάρουμε περισσότερα αποτελέσματα με άντρες μπορούμε να περάσουμε μία λίστα με τα βάρη ή αλλιώς τις πιθανότητες να εμφανιστεί τυχαία ένα φύλο.
random.choices(['Α', 'Θ'], weights=[0.7, 0.3], k=1)[0]
->'Α' Το k μας δείχνει πόσα αποτελέσματα θα μας επιστρέψει το random module. Επειδή αυτή η μέθοδος μας επιστρέφει τα αποτελέσματα σε μορφή λίστας, προσθέτουμε το 0 ανάμεσα σε brackets για να επιλέξουμε το στοιχείο μόνο του.
Στην συνέχεια θα καλέσουμε την μέθοδο για την δημιουργία τυχαίων ημερομηνιών γέννησης. Αυτή η μέθοδος μας δίνει την δυνατότητα να επιλέξουμε αν θέλουμε την ελάχιστη και την μέγιστη ηλικία. Ας υποθέσουμε ότι οι υπάλληλοι μας είναι μεταξύ 22 και 60 χρονών.
faker.date_of_birth(minimum_age=22, maximum_age=60)
->'1979-07-23' Για να δημιουργήσουμε τυχαία νούμερα τηλεφώνων θα χρησιμοποιήσουμε την μέθοδο bothify. Η οποία για κάθε # που θα περάσουμε μέσα στην μέθοδο θα μας δώσει ένα τυχαίο νούμερο. Επειδή όλα τα κινητά στην Ελλάδα ξεκινάνε με το 69 μπορούμε να κρατήσουμε τα δύο πρώτα ψηφία σταθερά.
Εάν θέλουμε ο αριθμός του κινητού να είναι μοναδικός μπορούμε να προσθέσουμε την μέθοδο unique.
faker.unique.bothify(text='69########')
-> '6949231930' Κάποια άλλα δεδομένα που μπορούμε να δημιουργήσουμε είναι ένα username και ένα password για κάθε εργαζόμενό μας για να μπορεί να συνδέεται στο δίκτυο της εταιρείας.
fakergr.unique.user_name()
fakergr.password()
->'mpafiti.margarita'
->'Gw^6USwaEd' Ενώ υπάρχει ξεχωριστή μέθοδος για την δημιουργία email μπορούμε να κρατήσουμε το ήδη υπάρχον username και να το χρησιμοποιήσουμε για την δημιουργία του εταιρικού email. Ας υποθέσουμε ότι την εταιρεία μας την λένε neobank με το domain name να είναι το neobank.gr. Χρησιμοποιώντας ένα f string μπορούμε να ενώσουμε το username με το domain name της εταιρείας μας και να δημιουργήσουμε το εταιρικό μας email.
f'{fakergr.unique.user_name()}@neobank.gr'
-> 'mpafiti.margarita@neobank.gr' Στην συνέχεια μπορούμε να δημιουργήσουμε τα δεδομένα για τον τόπο κατοικίας των εργαζομένων. Αν και υπάρχει μέθοδος που μας επιστρέφει όλη την οδό σε ένα αποτέλεσμα, είναι μία καλή πρακτική να έχουμε κάθε μέρος της οδού σε διαφορετικό αποτέλεσμα / κελί του πίνακα.
fakergr.city()
faker.bothify(text='#####')
fakergr.street()
random.randint(1, 500)
->'Σάμος'
->'39404'
->'Καλαμωτής'
->'159' Με αυτές τις τέσσερις μεθόδους θα πάρουμε την πόλη, τον ταχυδρομικό κωδικό, ο οποίος είναι πέντε τυχαία ψηφία. Το όνομα της οδού και το νούμερο του σπιτιού, το οποίο είναι ένα τυχαίο νούμερο από το 1 μέχρι το 500.
Μπορούμε επίσης να δημιουργήσουμε δεδομένα για το ΑΦΜ των εργαζομένων μας αλλά και για το ΑΜΚΑ τους. Όπως επίσης και τον τραπεζικό τους λογαριασμό στον οποίο θα στέλνουμε τον μισθό τους.
fakergr.unique.tin()
fakergr.unique.ssn()
fakergr.unique.iban()
->'305069550'
->'24120190755'
->'GR1081502380054861389999604'
Κάποια άλλα δεδομένα που θα χρειαστούμε είναι η θέση εργασίας κάθε εργαζομένου.
Αν και υπάρχει η μέθοδος fakergr.job(), αυτή η μέθοδος θα μας δώσει επαγγέλματα από όλους τους κλάδους. Αν και τα δεδομένα που δημιουργούμε είναι ψεύτικα και ίσως δεν έχει τόση σημασία να είναι εντελώς αληθοφανή θα προσπαθήσουμε να βάλουμε επαγγέλματα που είναι πιο κοντά στον τομέα της εταιρείας μας.
Θα χρησιμοποιήσουμε και εδώ το random module με την μέθοδο choices, όπως είχαμε κάνει και στην επιλογή του φύλου.
Εδώ επειδή έχουμε περισσότερες επιλογές θα φτιάξουμε μία ξεχωριστή λίστα, έξω από την μέθοδο choices, με τα ονόματα των επαγγελμάτων και μία δεύτερη λίστα με τα βάρη για κάθε ένα επάγγελμα.
Και στην συνέχεια θα καλέσουμε την μέθοδο choices.
jobs = [
'Μηχανικός Η/Υ - Τηλεπικοινωνιών και Δικτύων',
'Υπάλληλος Εξυπηρέτησης Πελατών',
'Στέλεχος Marketing',
'Επιστήμων Πληροφορικής και Η/Υ',
'Τεχνικός Ασφαλείας Δικτύων Η/Υ',
'Υπάλληλος Τράπεζας',
'Οικονομολόγος',
'Στατιστικολόγος',
'Ειδικός Πωλήσεων',
'Λογιστής'
]
weights = [0.15, 0.15, 0.15, 0.1, 0.1, 0.15, 0.05, 0.05, 0.05, 0.05]
random.choices(jobs, weights=weights, k=1)[0]
->'Στέλεχος Marketing' Χρησιμοποιώντας πάλι την μέθοδο choices μπορούμε να επιλέξουμε έναν τυχαίο μισθό από την λίστα μας για κάθε εργαζόμενό μας.
random.choices([11900, 14000, 16800, 21000, 25200, 28000, 35000, 42000],
weights=[0.2, 0.3, 0.15, 0.1, 0.1, 0.05, 0.05, 0.05])[0]
-> '14000' Κάτι άλλο που μπορούμε να δημιουργήσουμε είναι το πόσες μέρες άδεια έχει ακόμα ο κάθε εργαζόμενος. Θα πάρουμε την μέθοδο randint η οποία θα επιλέγει τυχαία ένα νούμερο από το 1 μέχρι το 30.
random.randint(1,30) Δημιουργία πίνακα εργαζομένων
Αυτά ήταν τα δεδομένα που θα δημιουργήσουμε για τον πίνακα των εργαζομένων.
Πάμε όμως να τα βάλουμε με την σειρά. Αρχικά θα φτιάξουμε μία μεταβλητή για το ID των εργαζομένων την οποία θα θέσουμε αρχικά ίση με το 0.
Στην συνέχεια θα φτιάξουμε μία συνάρτηση την οποία θα την ονομάσουμε employee().
Στην αρχή της συνάρτησης θα έχουμε μία μεταβλητή για το φύλο του εργαζομένου και χρησιμοποιώντας τον έλεγχο if ανάλογα με το αν είναι ‘Α‘ ή ΄Θ‘ θα επιστρέφουμε αντίστοιχα ένα αρσενικό ή ένα θηλυκό όνομα.
Επίσης θα προσθέτουμε συν 1 στην μεταβλητή ID του εργαζόμενου.
emp_id = 0
def employee():
sex = random.choices(['Α', 'Θ'], weights=[0.65, 0.35], k=1)[0]
if sex == 'Α':
first_name = fakergr.first_name_male()
last_name = fakergr.last_name_male()
elif sex == 'Θ':
first_name = fakergr.first_name_female()
last_name = fakergr.last_name_female()
global emp_id
emp_id += 1 Στην συνέχεια και ενώ είμαστε ακόμα μέσα στην συνάρτηση employee(), θα δημιουργήσουμε και θα υπολογίσουμε τις μεταβλητές για το επάγγελμα, την ημερομηνία γέννησης, τον αριθμό τηλεφώνου, το όνομα χρήστη, το email, τον κωδικό, την πόλη, τον ταχυδρομικό κώδικα, την οδό, τον αριθμό του σπιτιού, το ΑΦΜ, το ΑΜΚΑ, τον τραπεζικό λογαριασμό, τον μισθό και τις ημέρες άδειας για κάθε εργαζόμενο.
job = random.choices(jobs, weights=weights, k=1)[0]
birth_date = faker.date_of_birth(minimum_age=22, maximum_age=55)
phone_number = faker.unique.bothify(text='69########')
user_name = fakergr.unique.user_name()
company_email = f'{user_name}@neobank.gr'
pass_word = fakergr.password()
city = fakergr.city()
postcode = faker.bothify(text='#####')
street = fakergr.street()
street_number = random.randint(1, 500)
afm = fakergr.unique.tin()
amka = fakergr.unique.ssn()
iban = fakergr.unique.iban()
salary_y = random.choices([11900, 14000, 16800, 21000, 25200, 28000, 35000, 42000],
weights=[0.2, 0.3, 0.15,0.1, 0.1, 0.05, 0.05, 0.05])[0]
vacation_days = random.randint(1,30) Αφού υπολογίσουμε όλες τις μεταβλητές και ενώ βρισκόμαστε ακόμα μέσα στην συνάρτηση employee(), θα δημιουργήσουμε μία νέα μεταβλητή στην οποία θα περάσουμε μέσα με την μορφή “λεξικού” όλες τις μεταβλητές που αφορούν τον εργαζόμενο.
Τέλος θα επιστρέψουμε την τελευταία μεταβλητή.
emp_profile = {
'emp_id': emp_id,
'first_name': first_name,
'last_name': last_name,
'sex': sex,
'job': job,
'birth_date': birth_date,
'phone_number': phone_number,
'user_name': user_name,
'company_email': company_email,
'pass_word': pass_word,
'city': city,
'postcode': postcode,
'street': street,
'street_number': street_number,
'afm': afm,
'amka': amka,
'iban': iban,
'salary_y': salary_y,
'vacation_days': vacation_days
}
return emp_profile Η συνάρτηση employee() υπολογίζει τα δεδομένα για έναν εργαζόμενο, οπότε θα πρέπει να την τρέξουμε τόσες φορές όσες και οι εργαζόμενοι που υπάρχουν στην εταιρεία. Ας υποθέσουμε ότι έχουμε 400 εργαζόμενους, άρα θα τρέξουμε την συνάρτηση 400 φορές, θα χρησιμοποιήσουμε την εντολή for γι’ αυτή την δουλειά.
employees = [employee() for i in range(400)] Η νέα μεταβλητή employees είναι μία λίστα με όλους τους εργαζόμενους.
Για να δούμε καλύτερα τα δεδομένα θα μετατρέψουμε την λίστα σε έναν πίνακα ή αλλιώς dataframe. Για την δουλειά αυτή θα χρησιμοποιήσουμε την βιβλιοθήκη Pandas.
emp_df = pd.DataFrame(employees) Παρακάτω μπορούμε να δούμε τον πίνακα που δημιουργήσαμε.
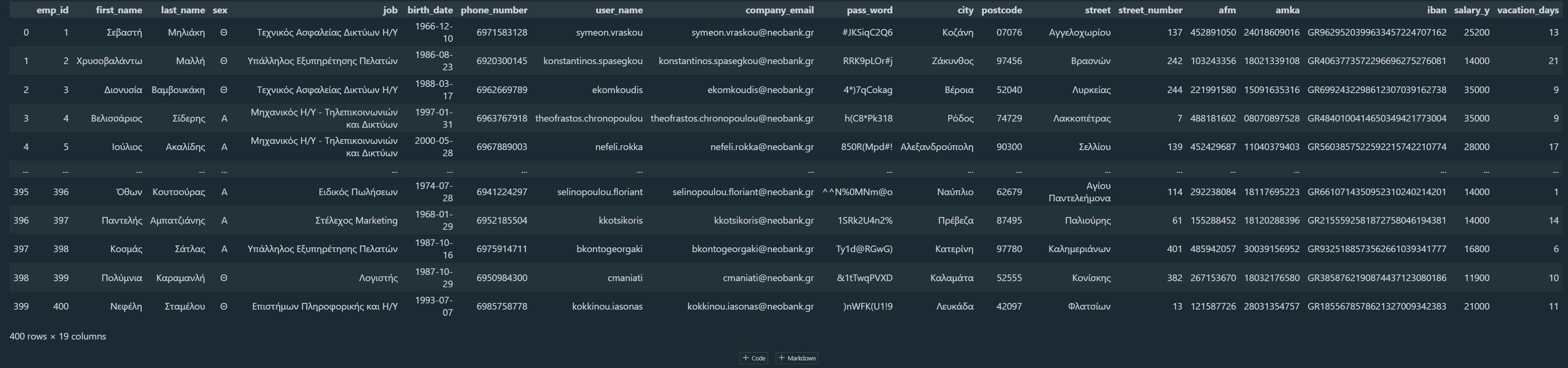
Εάν θέλουμε μπορούμε να χρησιμοποιήσουμε την βιβλιοθήκη Pandas για να αποθηκεύσουμε τον πίνακα σε αρχείο .csv.
emp_df.to_csv('employees.csv', index=False) Και αφού το αποθηκεύσαμε σε μορφή .csv μπορούμε να το ανοίξουμε με το Excel ή το Google sheets.

Δημιουργία πίνακα πελατών
Αφού δημιουργήσαμε τον πίνακα για τους εργαζόμενους μπορούμε εύκολα με τον ίδιο τρόπο να δημιουργήσουμε τον πίνακα και για τους πελάτες της εταιρείας.
Εδώ θα χρησιμοποιήσουμε μόνο το αγγλικό object της Faker μιας και οι πελάτες μας είναι από όλο τον κόσμο.
Ξεκινάμε δημιουργώντας την μεταβλητή ID για τους πελάτες, την οποία την βάζουμε ίση με το 999. Μιας και πρόκειται για διαφορετικούς πίνακες δεν θα υπήρχε πρόβλημα να έχουν το ίδιο ID πελάτες και εργαζόμενοι αλλά είναι μια καλή πρακτική να έχουμε διαφορετικό ID.
Όπως και πριν φτιάχνουμε μία συνάρτηση customer() η οποία αρχικά θα υπολογίζει το φύλο και στην συνέχεια θα δημιουργεί το όνομα ανάλογα το φίλο.
Επίσης προσθέτουμε συν 1 στην μεταβλητή ID.
cust_id = 999
def customer():
sex = random.choices(['M', 'F'], weights=[0.65, 0.35], k=1)[0]
if sex == 'M':
first_name = faker.first_name_male()
last_name = faker.last_name_male()
elif sex == 'F':
first_name = faker.first_name_female()
last_name = faker.last_name_female()
global cust_id
cust_id += 1 Στην συνέχεια υπολογίζουμε τις μεταβλητές για την ημερομηνία γέννησης, τον αριθμό τηλεφώνου, το όνομα χρήστη, τον κωδικό, το email, την χώρα, την πόλη, τον ταχυδρομικό κώδικα, την οδό, τον αριθμό του σπιτιού, το ΑΜΚΑ ή αλλιώς social security number και την ημερομηνία που δημιουργήθηκε ο λογαριασμός.
Μια άλλη καλή τεχνική είναι να μην αποθηκεύουμε απευθείας τους κωδικούς των πελατών μας αλλά να τους περνάμε πρώτα από έναν κρυπτογραφικό αλγόριθμο. Στο παράδειγμα αυτό θα χρησιμοποιήσουμε τον MD5.
birth_date = faker.date_of_birth(minimum_age=22, maximum_age=55)
phone_number = faker.unique.bothify(text='##########')
user_name = faker.unique.user_name()
email_provider = faker.free_email_domain()
email = f'{user_name}@{email_provider}'
pass_word = faker.md5()
country = faker.country()
city = faker.city()
postcode = faker.bothify(text='#####')
street = faker.street_name()
street_number = random.randint(1, 500)
ssn = faker.unique.ssn()
cust_acc_created = faker.date_between(pd.to_datetime('2015-01-01')) Τέλος, δημιουργούμε μία μεταβλητή η οποία θα αποθηκεύει όλες τις μεταβλητές για τον πελάτη σε μορφή “λεξικού”.
Και μετά θα επιστρέφει αυτή την μεταβλητή.
emp_profile = {
'cust_id': cust_id,
'first_name': first_name,
'last_name': last_name,
'sex': sex,
'birth_date': birth_date,
'phone_number': phone_number,
'user_name': user_name,
'email': email,
'password_hashed': pass_word,
'country': country,
'city': city,
'postcode': postcode,
'street': street,
'street_number': street_number,
'ssn': ssn,
'cust_acc_created': cust_acc_created,
}
return emp_profile Εφόσον δημιουργήσαμε τα δεδομένα για έναν πελάτη μπορούμε εύκολα με την εντολή for να δημιουργήσουμε τα δεδομένα για όλους τους πελάτες. Ας υποθέσουμε ότι η εταιρείας μας έχει 1.000.000 πελάτες, οπότε πρέπει να τρέξουμε την συνάρτηση customer() ένα εκατομμύριο φορές.
Το να τρέξεις την συνάρτηση ένα εκατομμύριο φορές είναι κάτι που θα πάρει αρκετό χρόνο ανάλογα και με τον υπολογιστή που τρέχει ο καθένας τη συνάρτηση, σε εμάς πήρε 7 μίση λεπτά για να ολοκληρωθεί.
customers = [customer() for _ in range(1000000)] Η μεταβλητή customers είναι μία λίστα με όλους τους πελάτες.
Για να δούμε καλύτερα τα δεδομένα θα μετατρέψουμε την λίστα σε έναν πίνακα ή αλλιώς dataframe χρησιμοποιώντας την βιβλιοθήκη Pandas.
cust_df = pd.DataFrame(customers) Παρακάτω μπορούμε να δούμε τον πίνακα που δημιουργήσαμε.
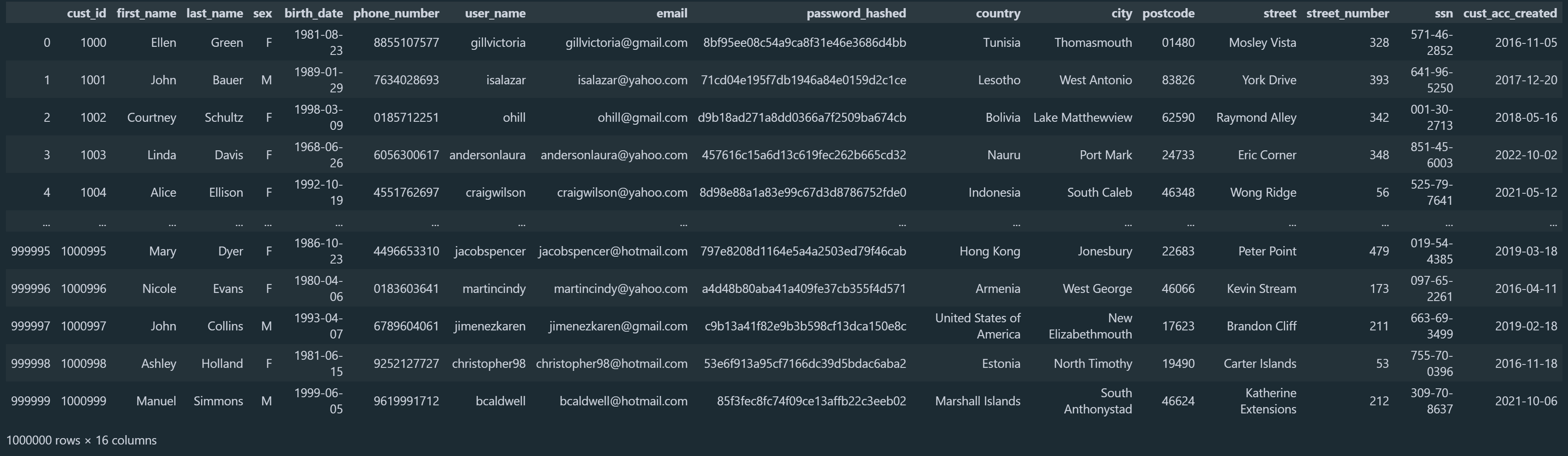
Εάν θέλουμε μπορούμε να χρησιμοποιήσουμε την βιβλιοθήκη Pandas για να αποθηκεύσουμε τον πίνακα σε αρχείο .csv.
cust_df.to_csv('customers.csv', index=False) Και αφού το αποθηκεύσαμε σε μορφή .csv μπορούμε να το ανοίξουμε με το Excel.
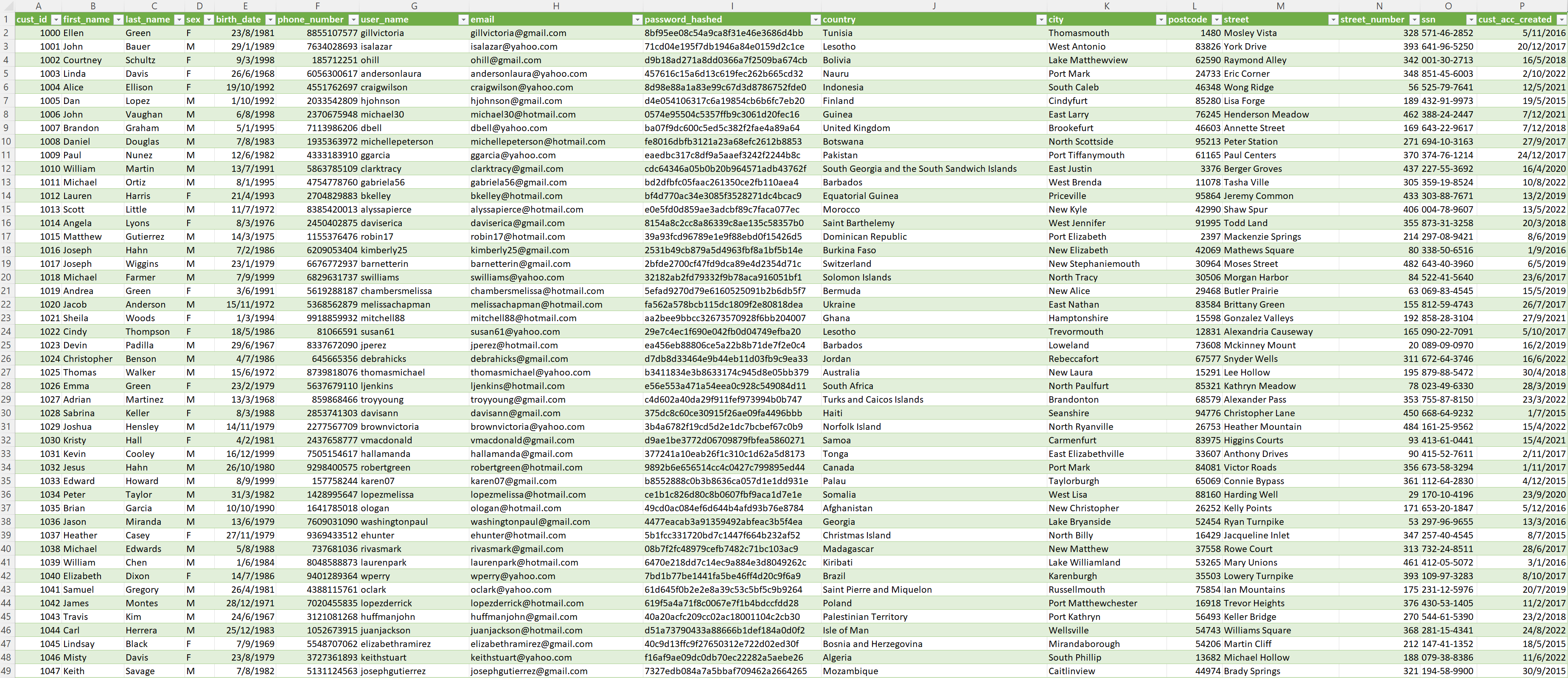
Επίλογος
Σε αυτό το μάθημα είδαμε πως μπορούμε να χρησιμοποιήσουμε την βιβλιοθήκη Faker της Python για να δημιουργήσουμε τυχαία ψεύτικα δεδομένα με όσο πιο αληθοφανή τρόπο μπορούσαμε.
Αν βρήκες ενδιαφέρον αυτό το μάθημα μπορείς να μας κεράσεις έναν καφέ ή να το μοιραστείς με τους φίλους στα social media.